
Proxmox VE 6.1でCephにOSDを登録するメモ
最初に
前記事で各ノードにCephインストールとモニター・マネージャー登録が完了しました
現在の状況はこちら
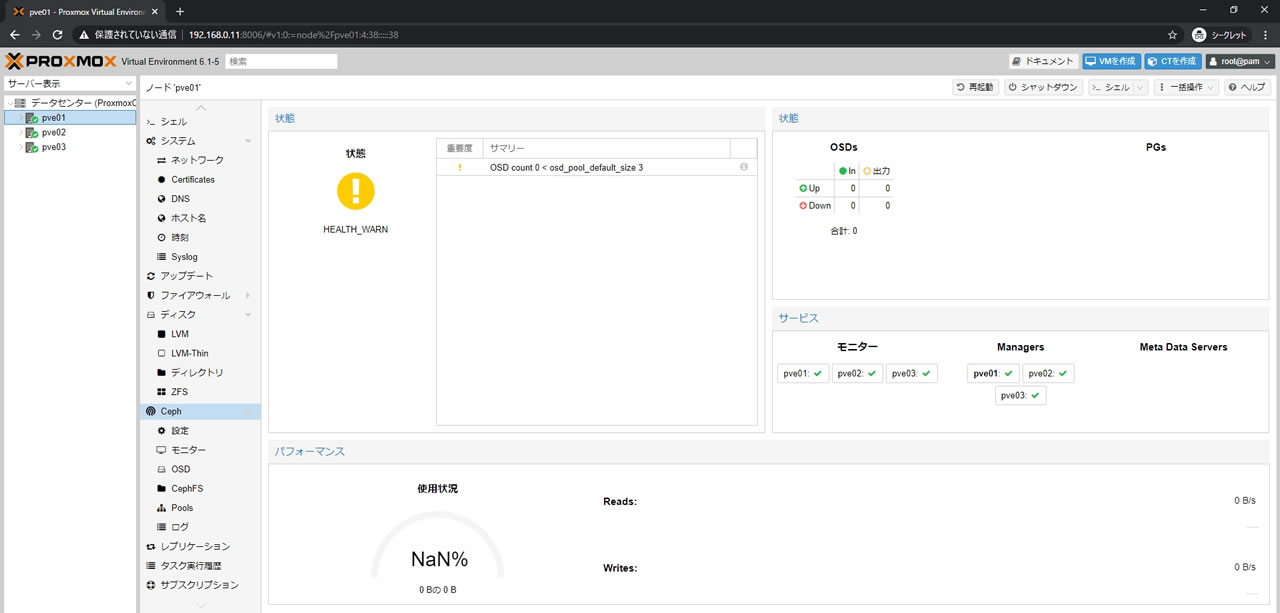
状態がHEALTH_WARNになっている通り
OSDがまだ登録されていないのでCephはまだ利用できません
サマリーに「OSD count 0 < osd_pool_default_size 3」と記載されていることからも
現在のOSD countが0、動作させるためには3以上の登録が必要なのがわかります
今回は3台体制なので各ノードごとに1OSDを登録してまずは使えるようにしていきます
OSDの登録
pve01の画面からCeph -> OSDを選択
現時点ではOSDは登録していないので何も表示されてません
上部にある「作成: OSD」ボタンを選択します
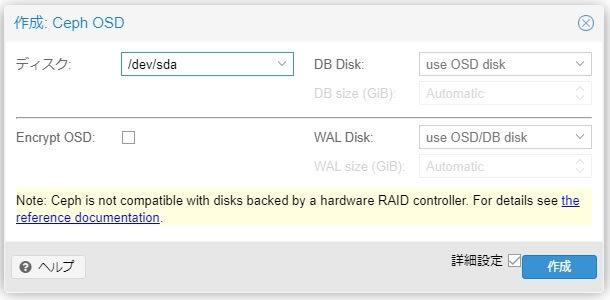
Ceph OSDの登録画面が出てきます
ディスクはOSDとして登録するデバイスを指定します
Encrypt OSDは暗号化オプションですが今回は設定してません
DB Disk/WALDiskは前記事で説明したDB/WALに関するオプションです
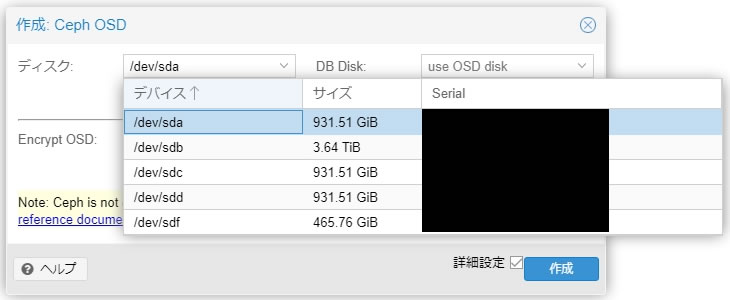
ディスクに指定するデバイスは丸ごとOSDに割り当てることになります
ディスクがHDDの場合はDB/WAL領域をSSDに割り当てて高速化できます
DB/WALに関してはデバイス丸ごと専有するわけではないので
空き容量があれば1台のSSDで複数のOSDのDB/WAL Diskとして共有して利用可能です
DB/WALの確保容量はOSD容量を基に計算されていて
指定しなかった場合はDBは10%、WALは1%だそうです
ディスクはプルダウンでデバイスを選択できます
作成ボタンを選択してDone!と表示されればOKです
OSDを1つ登録完了した段階ではこの状態になります
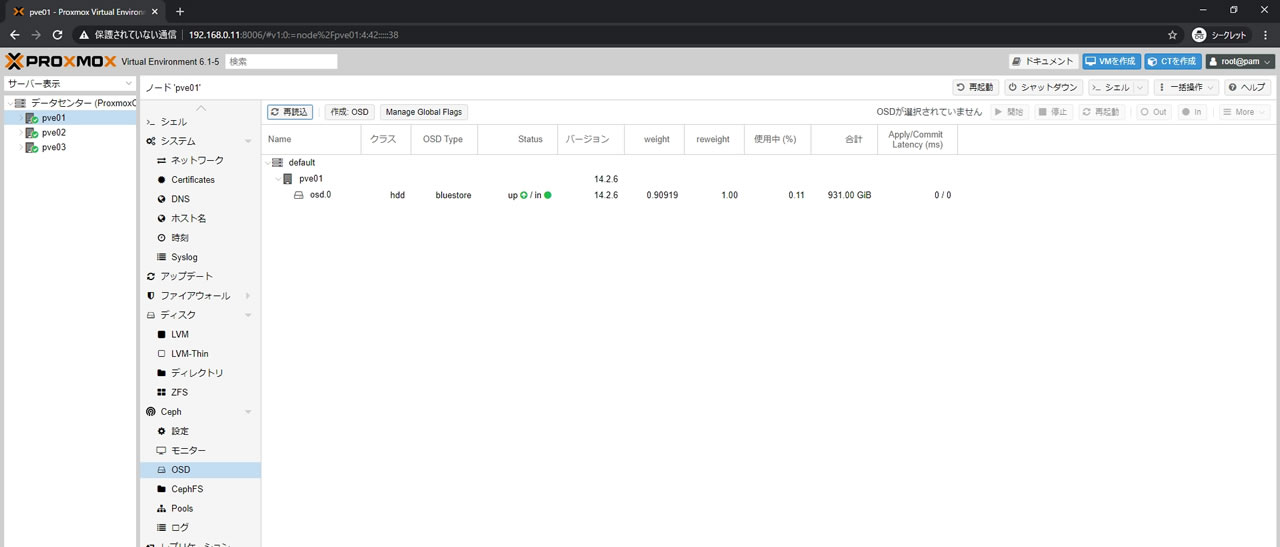
Cephの状態がこちら
サマリーのOSD countが1になっていてOSDsの部分も1になっていればOK
パフォーマンスの使用状況もNaNから0%表記に変わりました
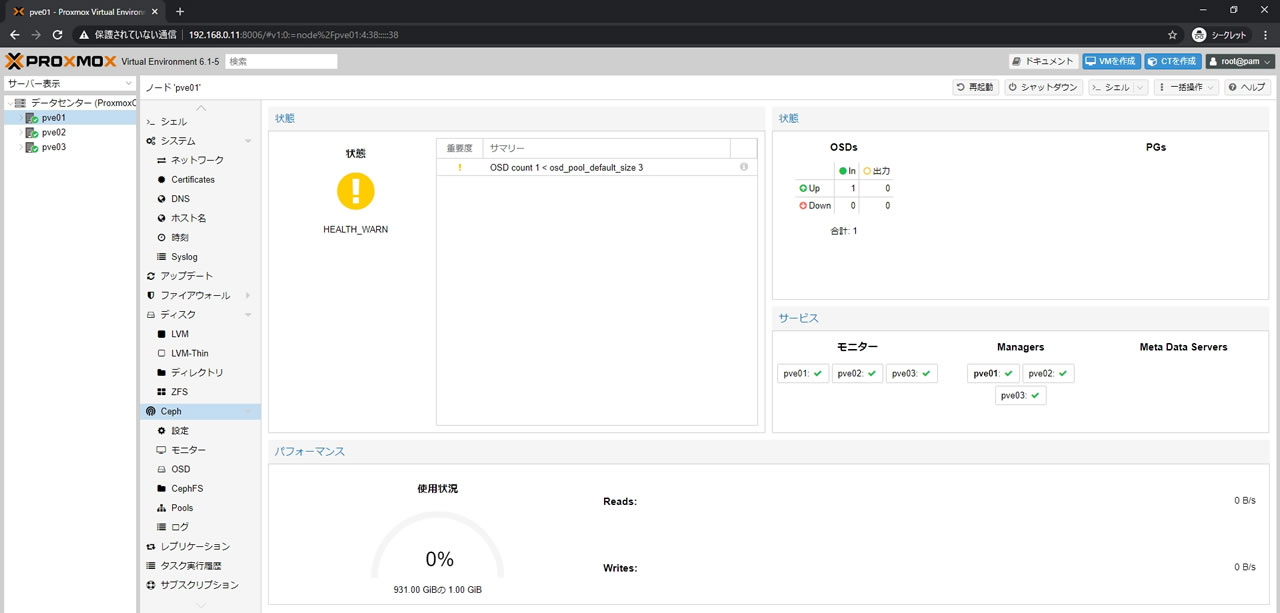
残るpve02/pve03のノードでも同様にOSDを登録していきます
全3台にOSDを登録した結果がこちら
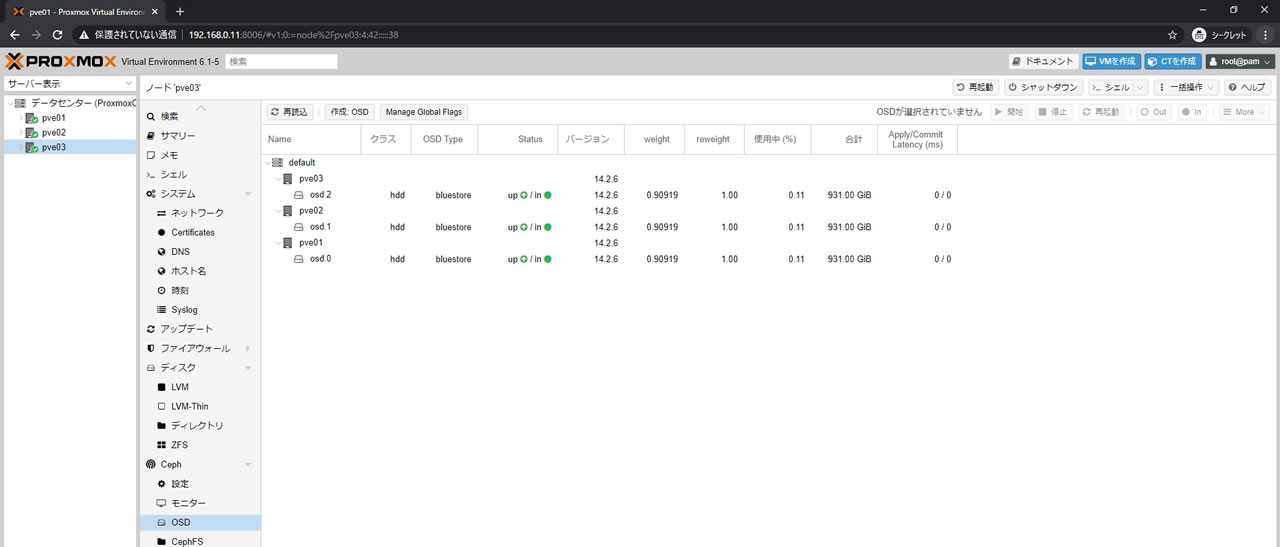
OSDが3台になったのでCephの状態もHEALTH_OKになり正常ステータスになりました
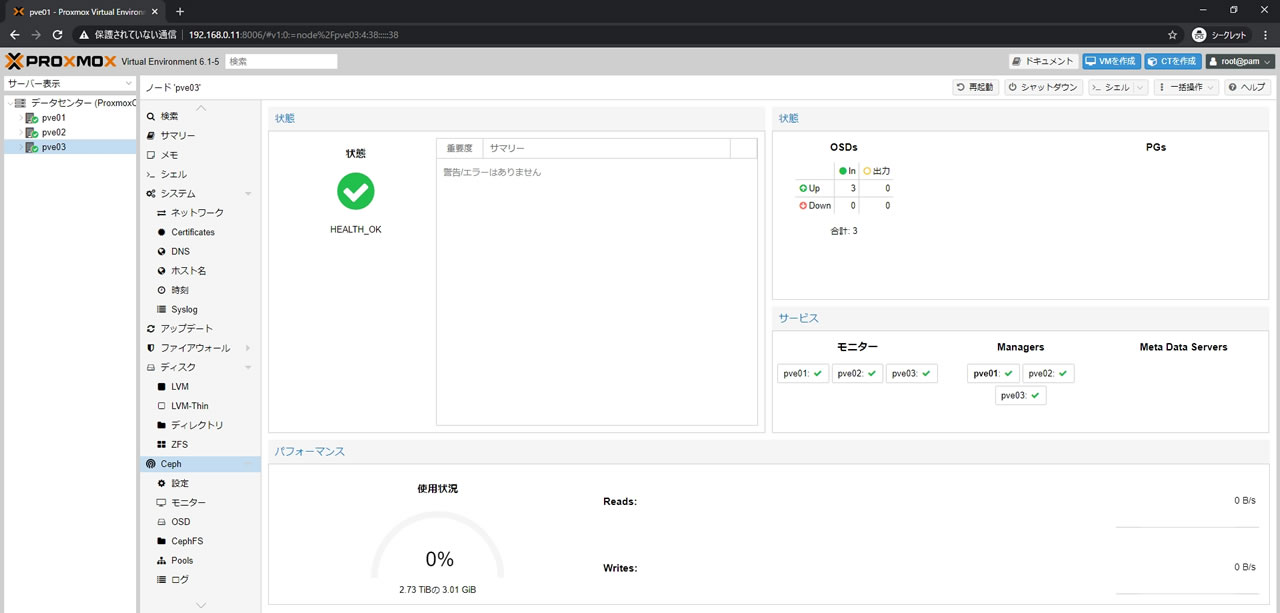
クラスター全体のサマリー画面でもCephはHEALTH_OK

各ノードのディスク画面ではOSDに割り当てたデバイスの使用状況が
「Ceph osd.0 (Bluestore)」と表示されます
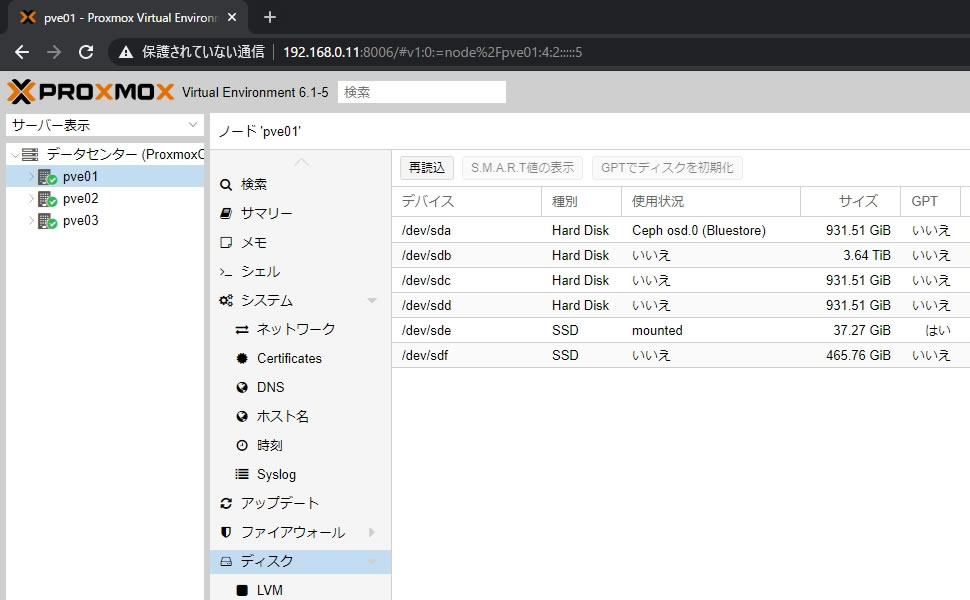
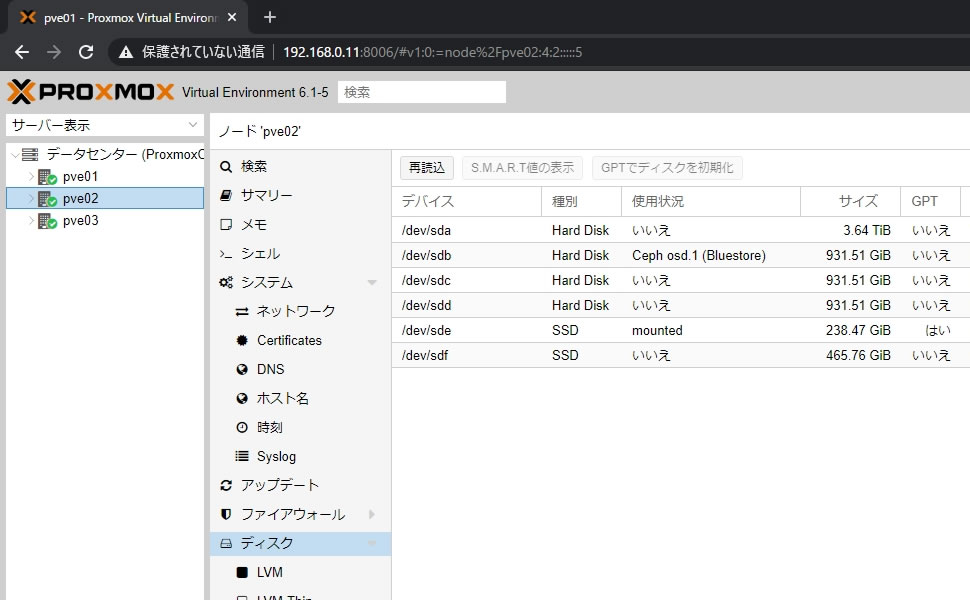

ちゃんとOSDの番号も表示されるのでデバイスの障害時でも見分けが簡単になってます
CephFSとCeph/RBDについて
OSDを登録してCephが正常ステータスになりこれで使えるかと思いきや
この段階でもProxmoxからはまだ利用できません
現時点では入れ物全体の箱を用意できた状態のようなもので
実際にProxmoxから使う為にはどう使うかを設定する必要があります
しかしその設定をする前にProxmoxのストレージタイプを理解する必要がありますので
簡単に説明を入れておきます
Proxmoxのストレージタイプは大きく分けてファイルレベルとブロックレベルの2種類あって
よく使う方式でいうとNFSやCIFSがファイルレベル、iSCSIはブロックレベルです
Cephの場合はCephFSがファイルレベルでCeph/RBDがブロックレベルになります
アクセス速度はブロックレベルの方が高速とされていているので
VM保存先など速度が重要なデータにはCephFSよりCeph/RBDが推奨となっています
ESXiの場合はブロックレベルでのアクセスになるiSCSIでも
vmfsフォーマットを使う関係でVMの保存先はもちろんのこと
ESXiを通せばFTPやデータストアブラウザからtxt・iso・zip等どんなファイルでも
アップロードできるので意識する必要はありませんが
Proxmox/Cephの場合はブロックレベルのCeph/RBDではVM保存先には使用できても
ファイルを個別にアップロードできない為、ISOファイルをアップロードできません
つまりCeph/RBDだけ作ってもVM作成時に必要なOSイメージファイルを
保存しておく場所がない為、別途ファイルレベルでアクセス可能な
CephFSかNFSなどを用意する必要があります
(容量が許せばProxmoxOSインストール先の空きスペースでもアップロード可能)
対応策としてはVM保存先も全てCephFSで運用するか
Ceph/RBDとCephFSを両方作成するか
Ceph/RBD上にNFSサーバとなるVMを作成してISO倉庫にするかです
Ceph/RBDとCephFSを両方作成するのが一番便利なようにも見えますし
実際に環境が許せばそれで問題はないのですが
現実問題としてCephにはPG値という制限があるので
一般的にはISO倉庫の為だけにCephFSを作成するのは避けられています
PGとはPlacement Groupの略で直訳で配置グループ
CephではOSDの数を基にクラスタ全体のPG値を算出し
そのPG値の範囲内でしかプールを作成できません(CephFSやCeph/RBDがプールです)
配置グループ自体は名前の通りでプールを何分割のグループで管理するかという数値で
128のPG値で作成したプールの場合は内部では128個に分割されて管理されることになります
(例えばHDD障害などの対応でリマップやリカバリーが走る場合はPGごとに処理されます)
初期値だとmon_max_pg_per_osdは250
mon_max_pg_per_osdが1OSDあたりのPG値ですので
今回作成したOSDが3つの構成なら250×3=750が全体のPG値となります
プールを作成する際にどれくらいのPG値を割り当てるかはpg_numで自由に設定できますが
Ceph公式の推奨値は5OSD以下で128、5~10OSDで512、10~50OSDで1024
PG値は多すぎても少なすぎてもパフォーマンスが低下するので
まずは推奨値のまま使ってみましょう
今回は3OSD構成なので1プールあたり128のpg_num設定とすると
プールごとのサイズ設定を3に設定するとしたら128×3=384
同様のプールを2つ作成すると384×2=768
しかし全体のPG値が750なのでPG値不足で2つ目のプールは作成できません
実際には負荷の少ない片方のpg_numを64に減らしたり
mon_max_pg_per_osdの数値はceph.confで変更可能なので
2つのプールを3OSDに押し込めるのは可能ですが
PG値が大事なのは変わりないのでCeph/RBDとCephFSを両方作成する場合は
OSD数とプール数を事前に考慮してから構築した方が無難です
Ceph/RBDのプールを作成
pve01の画面からCeph -> Poolsを選択
Ceph/RBDを作成する場合は上部にある「作成」ボタンを選択
Ceph Pool作成画面が表示されます
名前はプール名なので自由に設定してください
サイズと最小サイズはクラスタ作成時のNumber of replicasとMinimum replicasと同様で
サイズがレプリカ数で最小サイズが動作させる為のOSD数
Crush Ruleは文字通り障害時のルールですがとりあえずデフォルトのreplicated_ruleを使用
pg_numが先ほど説明したPG値でこれも推奨値の128で進めます
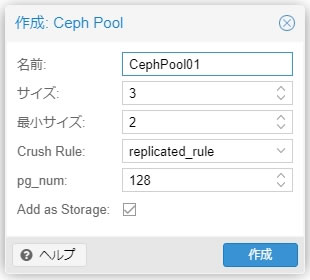
問題なく作成できたらDone!の表示で完了します
もしPG値が不足した場合はTask failedになります
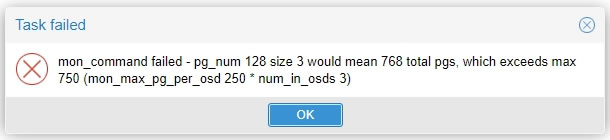
mon_command failed - pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
この場合は指示されたプールを作るには追加で128×3が必要で
既存分を合わせると全部で768のPG値必要なのに
今の構成には250×3=750しかないという状態です
無事に作成した場合のPools画面がこちら
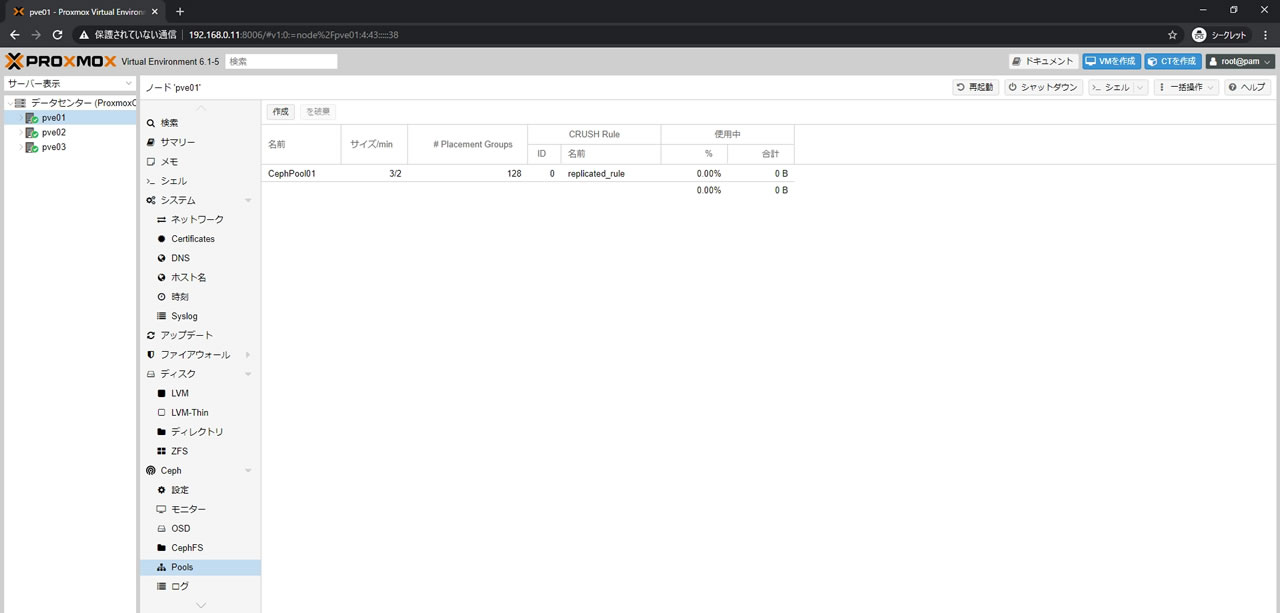
Cephのサマリー画面がこちら
左メニューの各ノードにCephPool01が追加されています
そして右上にあるPGsに今回登録した128のpg_numが反映されています
下部の使用状況にある容量表記は登録したOSDの総合計のようです
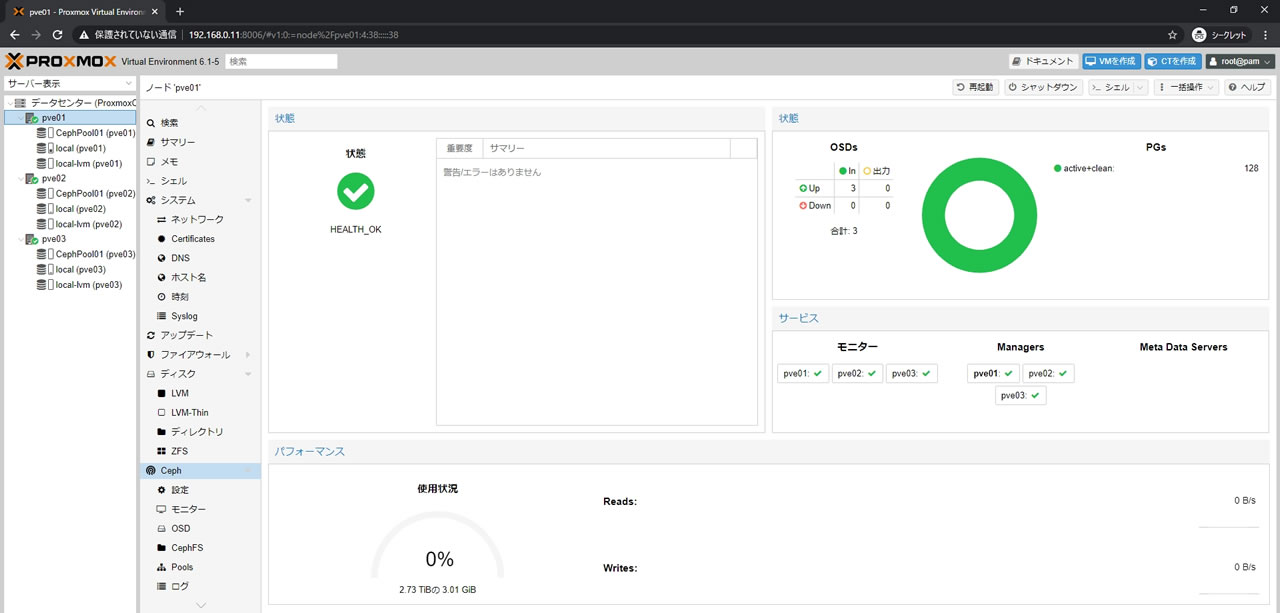
CephPool01のサマリー画面がこちら
容量は883.45GiB表記となりました
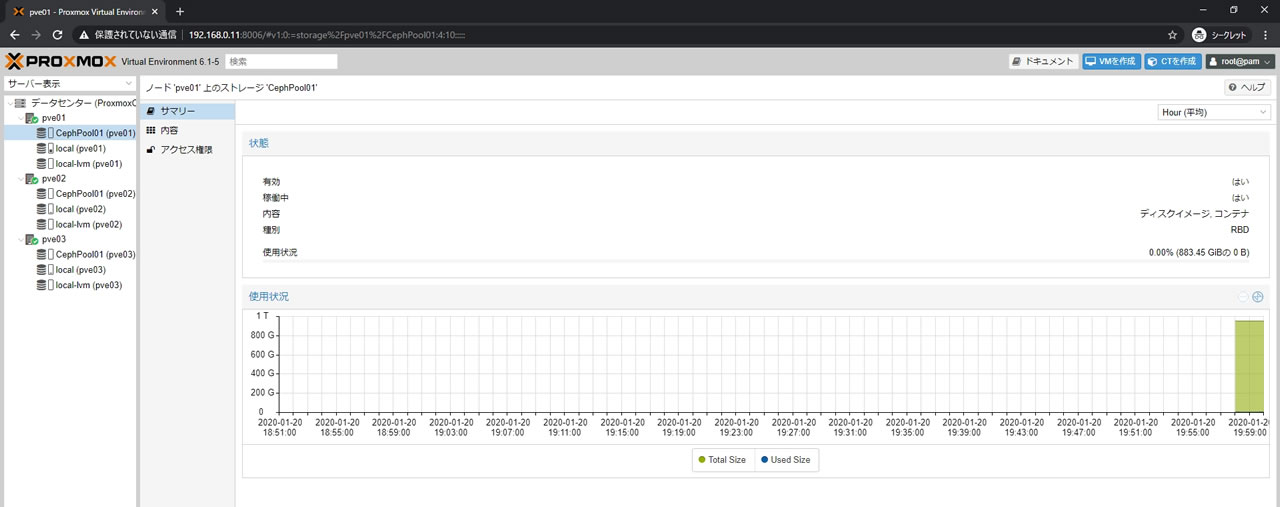
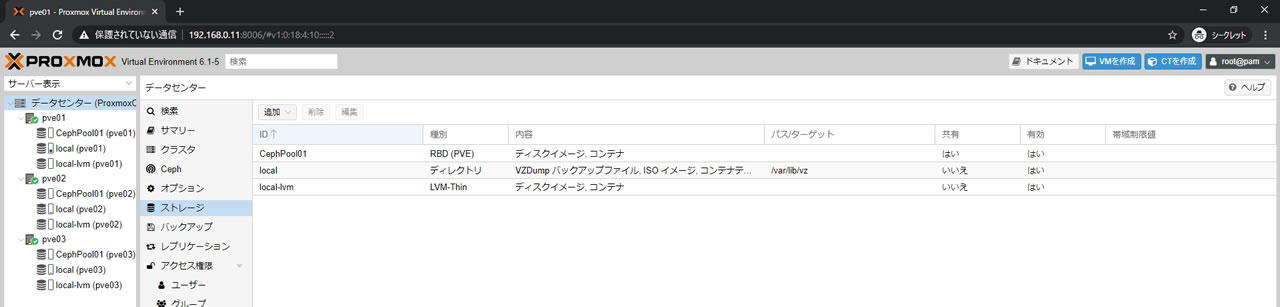
ストレージ一覧の画面がこちら
CephPool01の内容にISOイメージがないことを確認できます
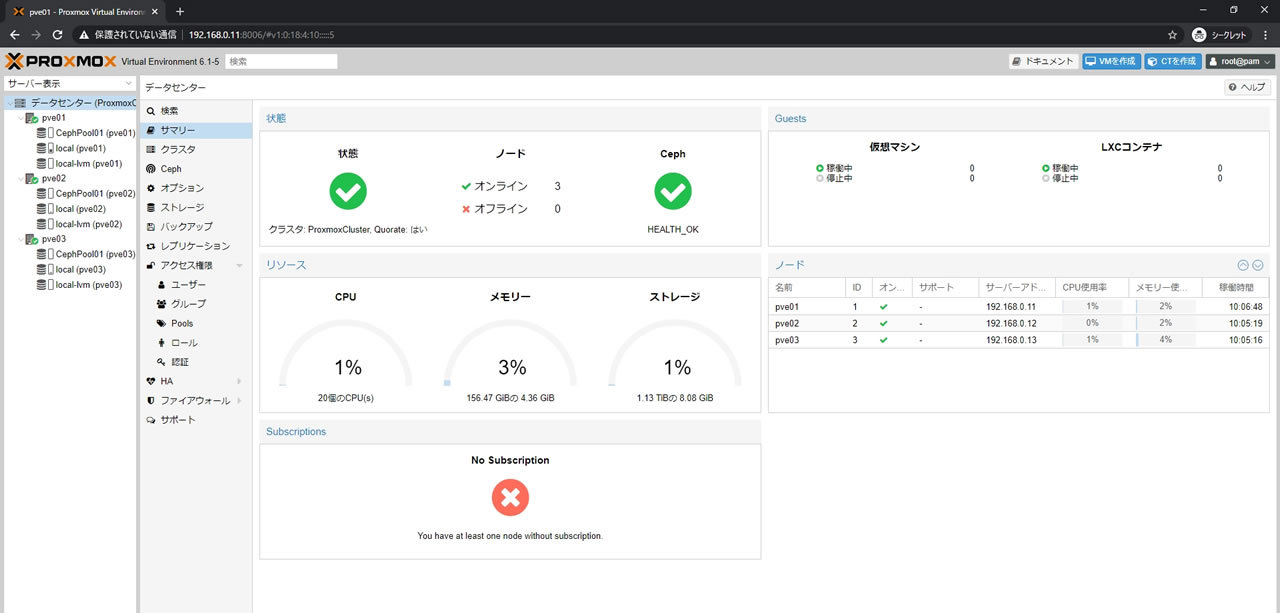
データセンターのサマリー画面でもストレージが増えているのが確認できます
Pool登録前が276.57GiBだったのが1.13TiBへ増加しました
CephFSのプールを作成
CephFSのプールを作成していきますがプールを作成する前に
Metadata Serverが必要なので先にMetadata Serverを作成・登録してから
CephFSのプールを作成します
Metadata Server作成
Metadata Serverは名前の通り、CephFSのメタデータを管理するサーバのことで
Cephのマネージャーと同様の仕様で常に動作するのは1台のみで
他はスタンバイ状態で待機になります
最低1台あればCephFSの動作に問題ありませんが
冗長性確保の為こちらも3台体制にしておきます
pve01の画面からCeph -> CephFSを選択
Metadata Serversが登録されていないので「CephFSを作成」ボタンが選択できません
まずはMetadata Serversの「作成」ボタンを選択します
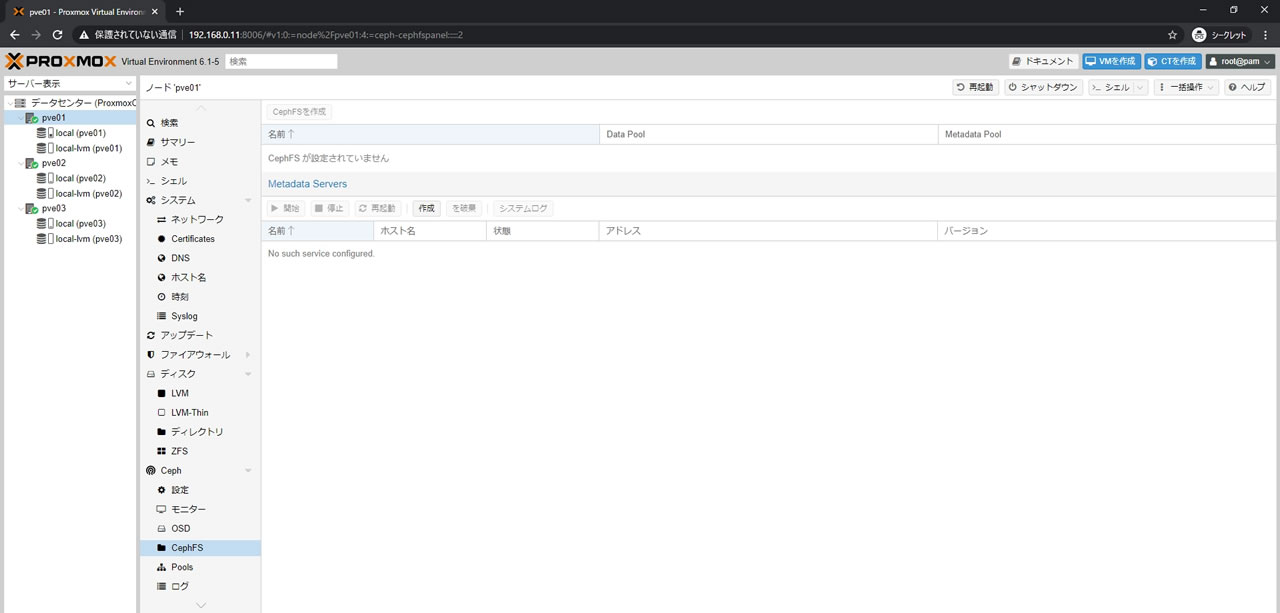
ホスト名はプルダウンから選択します
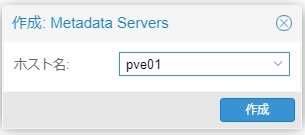
pve01が登録された様子がこちら
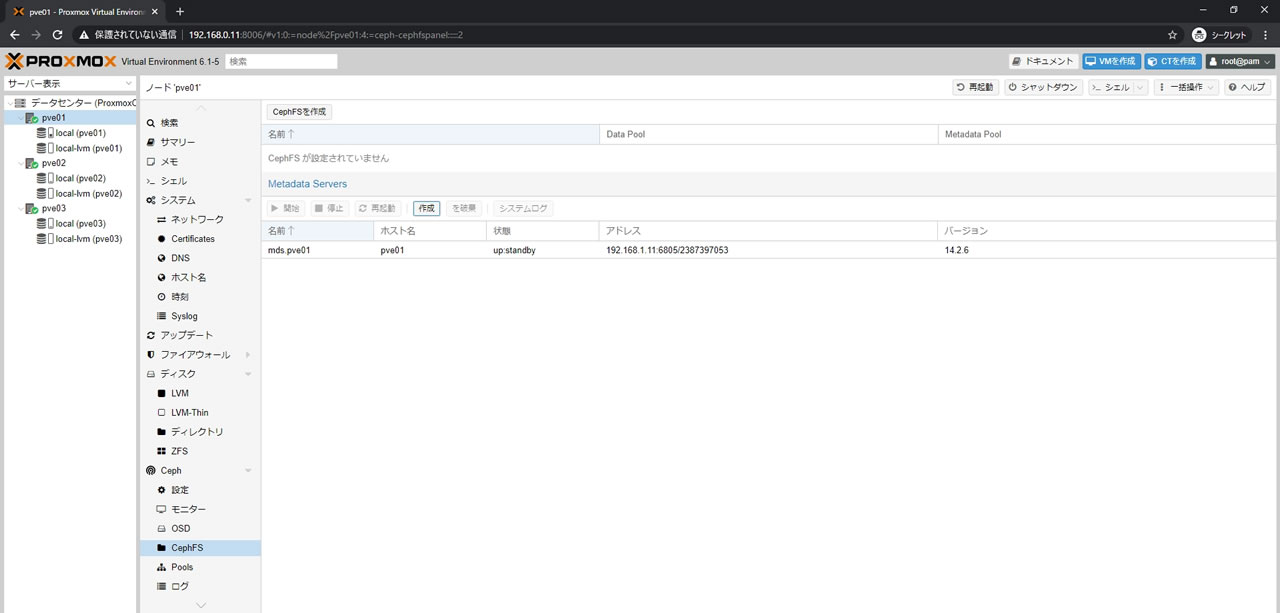
残りのpve02/pve03も同様に登録後、3台登録した状態がこちら
Cephのモニター画面でもMeta Data Serversに3ノード登録されているのを確認します
これでMetadata Serverの準備は完了です
CephFS作成
pve01の画面からCeph -> CephFSを選択
「CephFSを作成」ボタンを選択します
名前はプール名なので自由に設定してください
Placement GroupsはPG値のことです
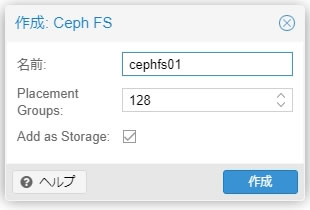
無事に作成完了できれば「TASK OK」になります
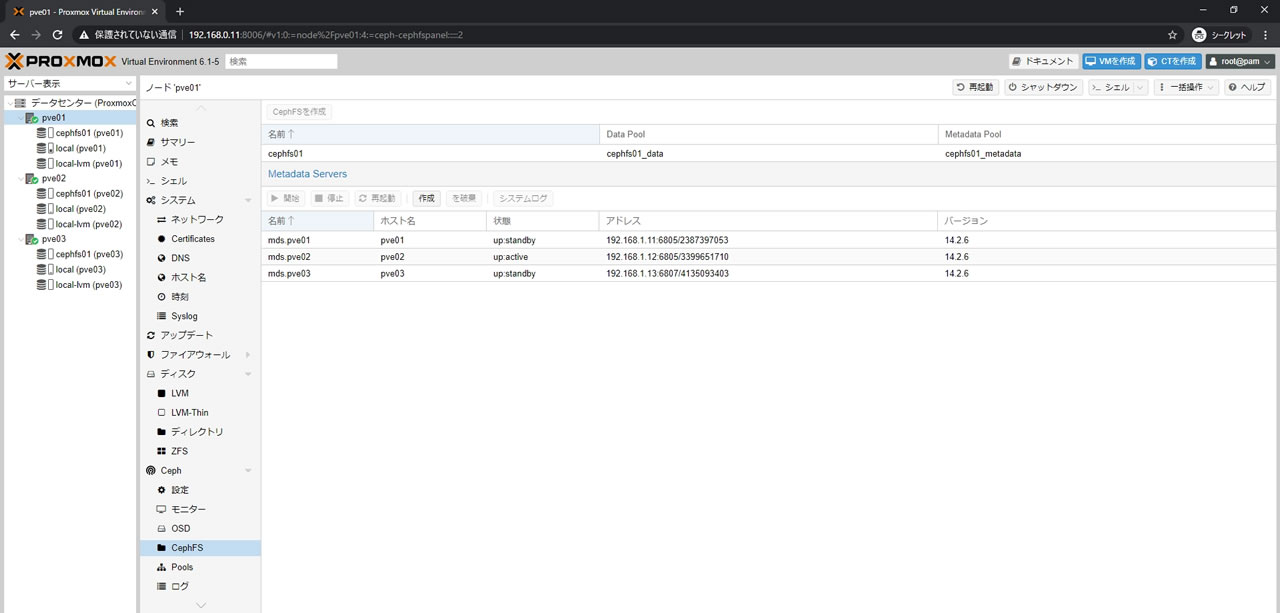
CephFS作成後の画面がこちら
Data PoolとMetadata Poolが登録されているのがわかります
そして左メニューの各ノードにもcephfs01が登録されています
Metadata Serverはpve02が自動で選ばれてactiveになっています
Cephモニター画面はこちら
PGsは160になっています
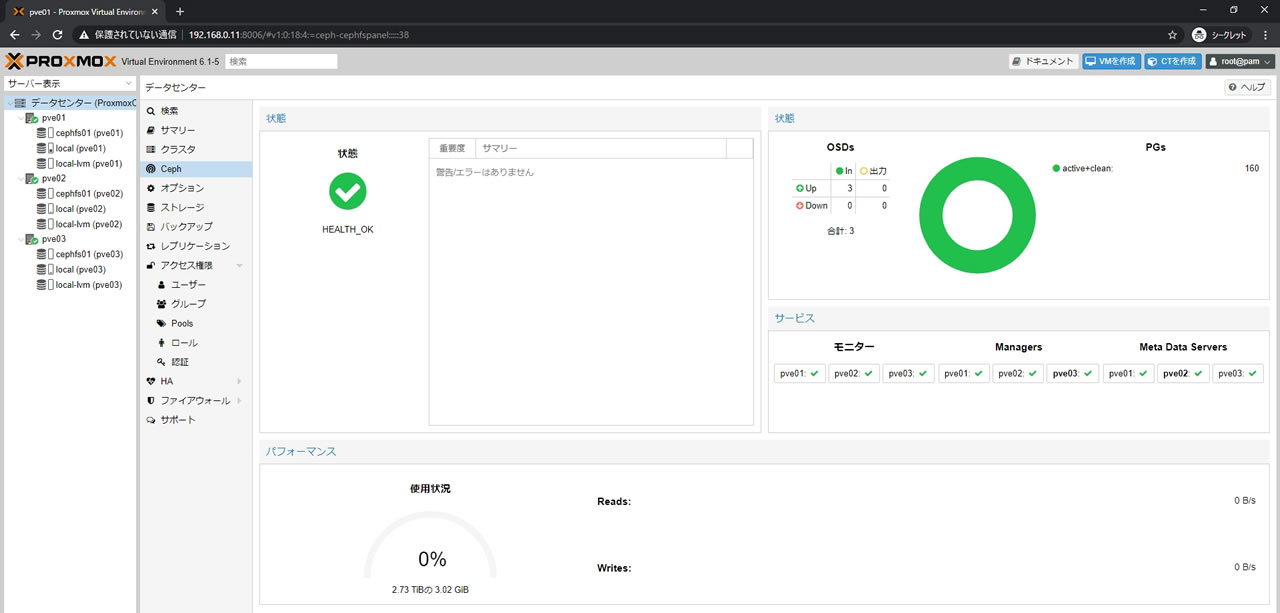
CephFSの作成画面でPlacement Groupsの値を128に設定しても
PGs値が160になっている理由はこちらです
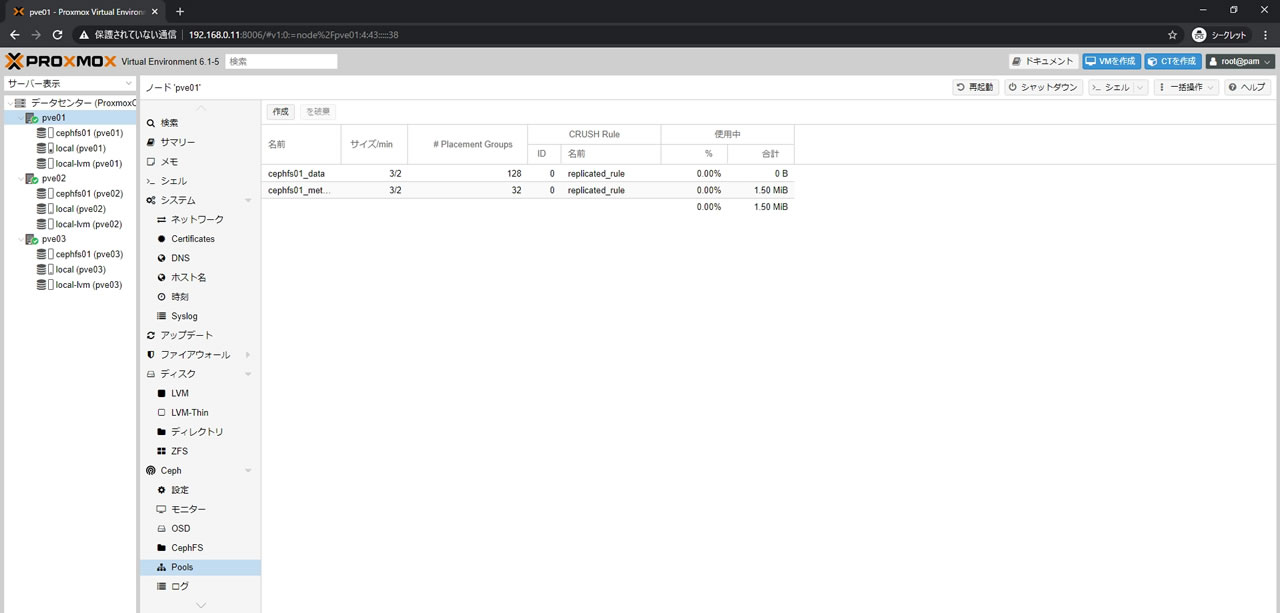
Data Poolに128、Metadata Poolに32が割り当てられたので足して160
Ceph/RBDより若干PG値の消費が多くなりますのでその点には注意です
最後に
ESXiからの移行組であればProxmox/CephはPG値の概念(というか縛り)と
Ceph/RBDだとファイルを直接アップロードできないのが
最初にまず不便に感じる点かなと思います
Cephに関しては大きく分けて昔のFileStoreタイプと現行のBlueStoreタイプがあるので
Cephのことで検索する場合はBlueStore対応の記事かどうかをまず確認した方が無難です

コメント