
Proxmox VE 6.1 + CephでOSD構成を変更したメモ
最初に
今回はCephのOSD構成を変更する手順に関する記事になります
3SSD→3HDD
今回は前記事まで使っていたSSDのみでの構成から
HDDのみの構成へ変更した時の手順になります
SSDはSSD SATA Crucial MX500 500GB
HDDはHDD ST1000DM010 1TB 7200rpm
今回の手順はSSD→HDDに限らず
HDD→SSDやHDD→新HDDなどのOSD交換全般で利用可能
現在の構成
3ノードクラスタで各ノードSSD 512GBが1台の3OSD構成です
SSDx1の速度計測の記事で使った構成と同一になります
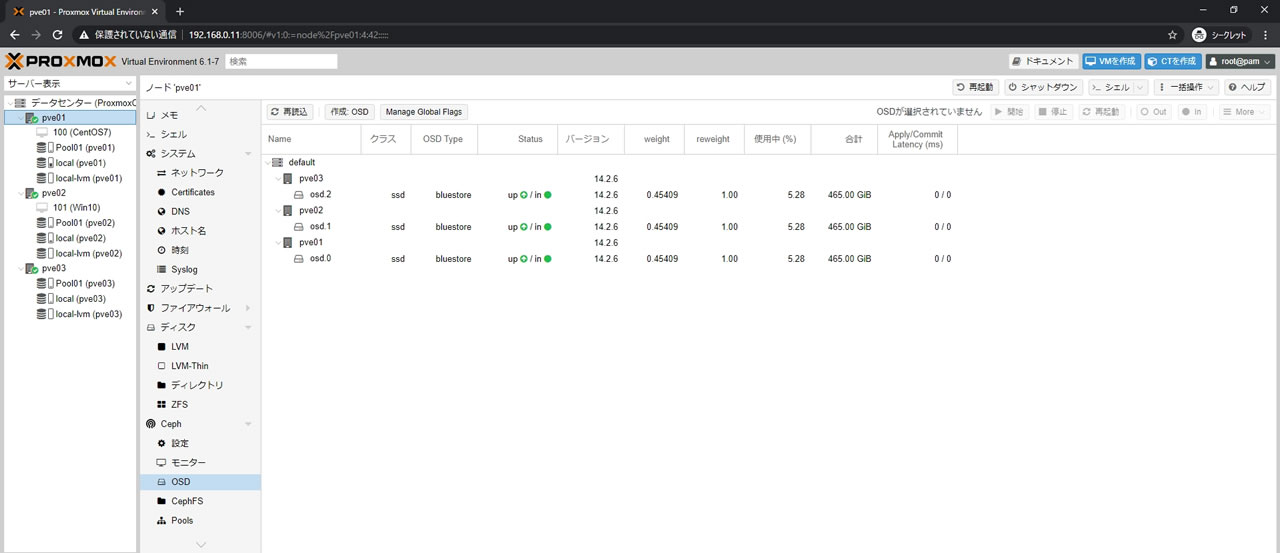
各OSDはDB/WALともにOSD Disk使用になります
Pool01という名前でプールを作成済
プール内にはベンチマーク用VMが2つ残ったままになっています
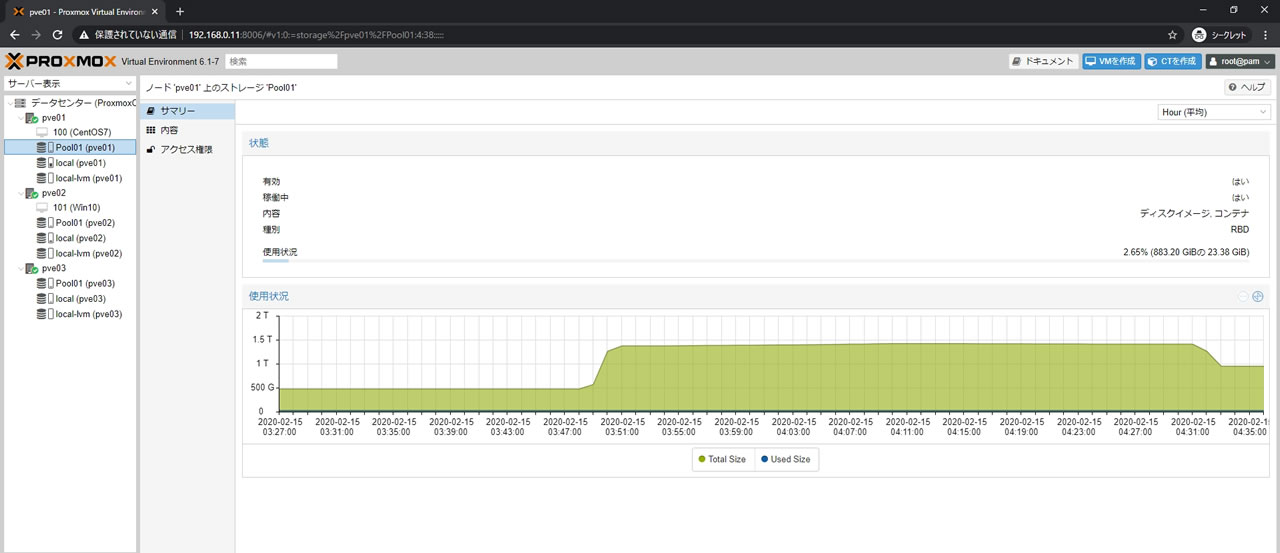
Pool01ストレージのサマリー画面で全体容量は440.56GiBになっています
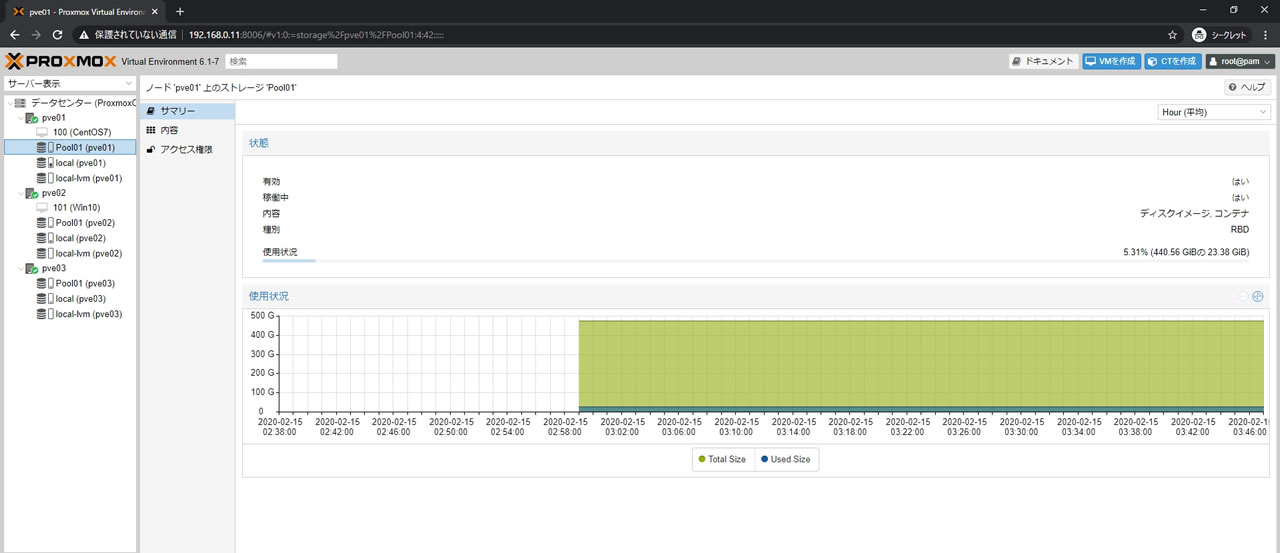
Cephのサマリー画面はこんな感じです
プールのpg_numは128
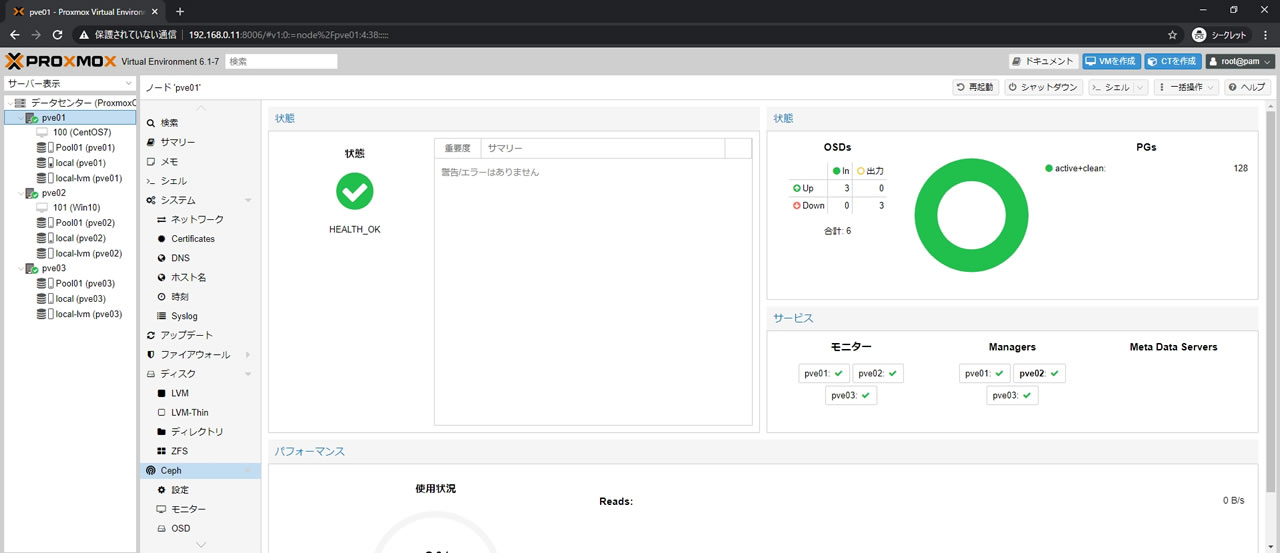
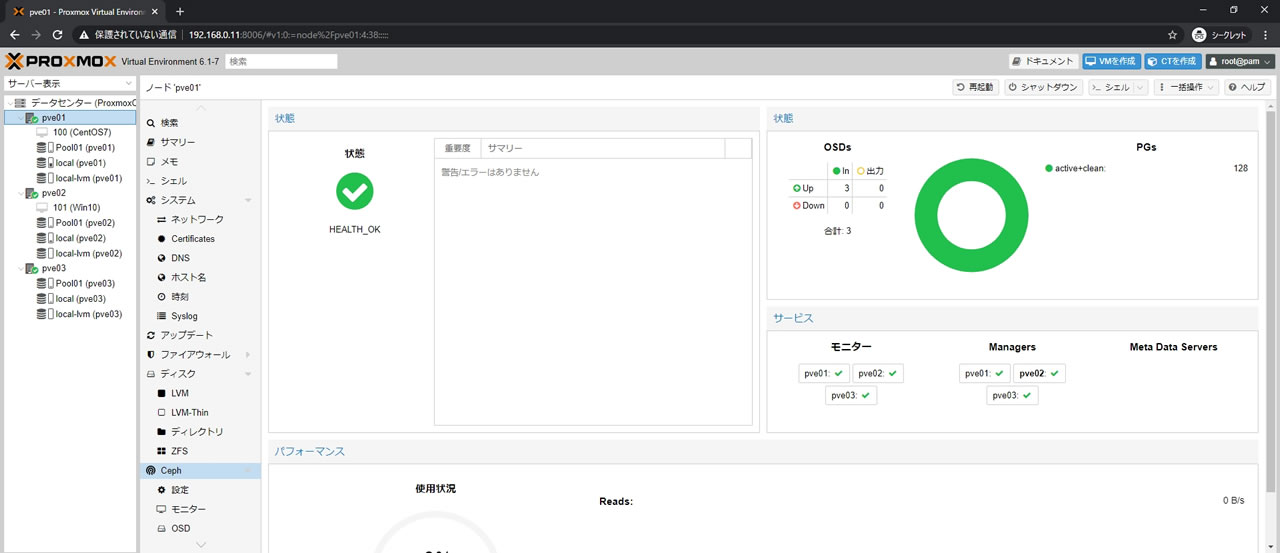
問題なくHEALTH_OK表記になっています
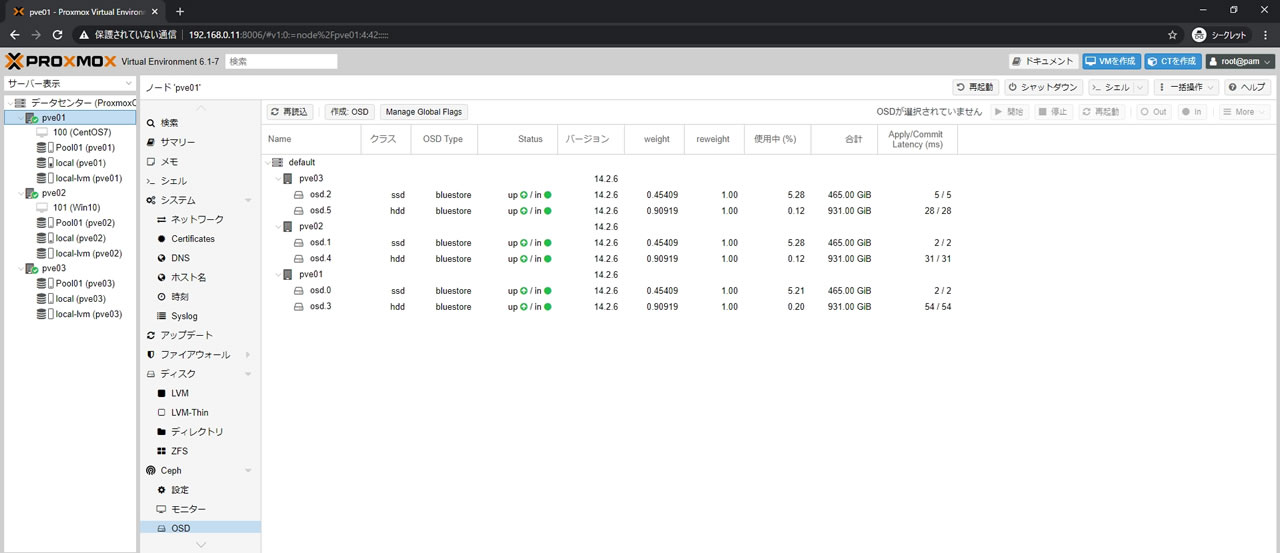
交換先のディスクをOSD登録
交換先のディスクをOSDに登録していきます
今回はDB/WALは指定せず

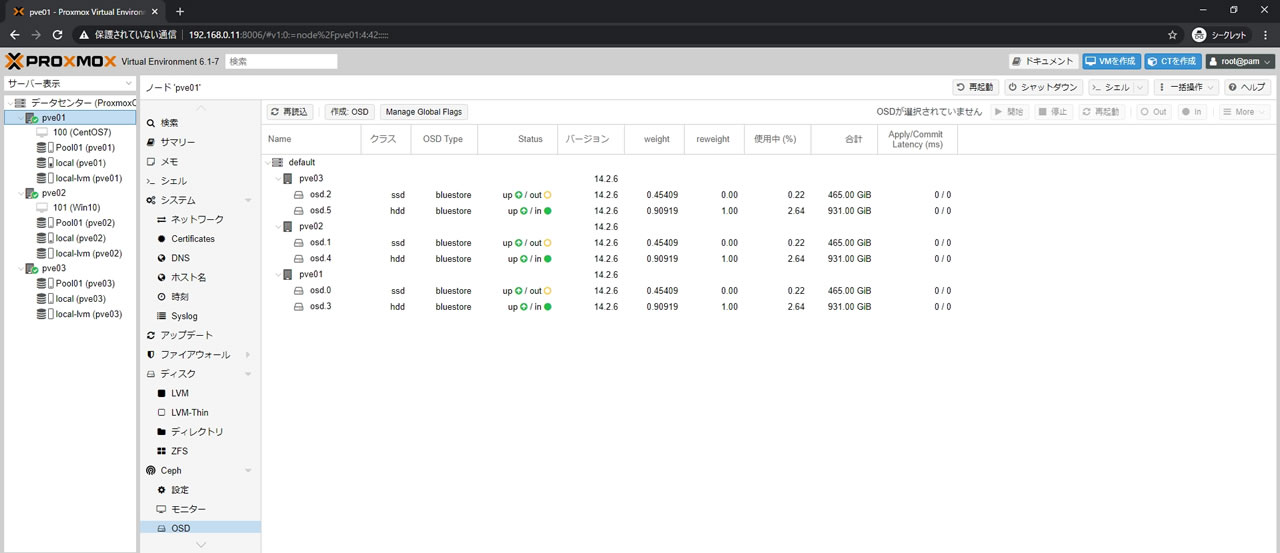
3ノード全てにHDDをOSD登録した結果がこちら
全部で6OSDになっていてクラス項目でssdとhddになっているのがわかります
レイテンシが表示されているのは既にリマップ処理が開始されているからです
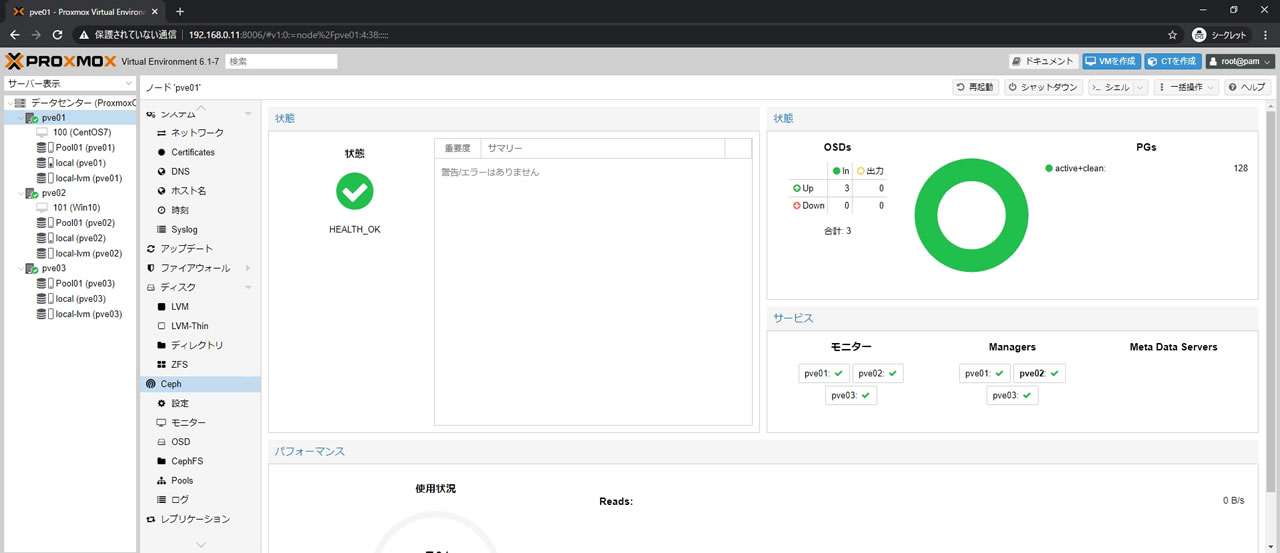
Cephのサマリー画面がこちら
PGsでは全てのPGにactiveがついているのでプール自体は利用可能状態ですが
リマップ処理が行われているので普段のアクセス速度はもちろんでません
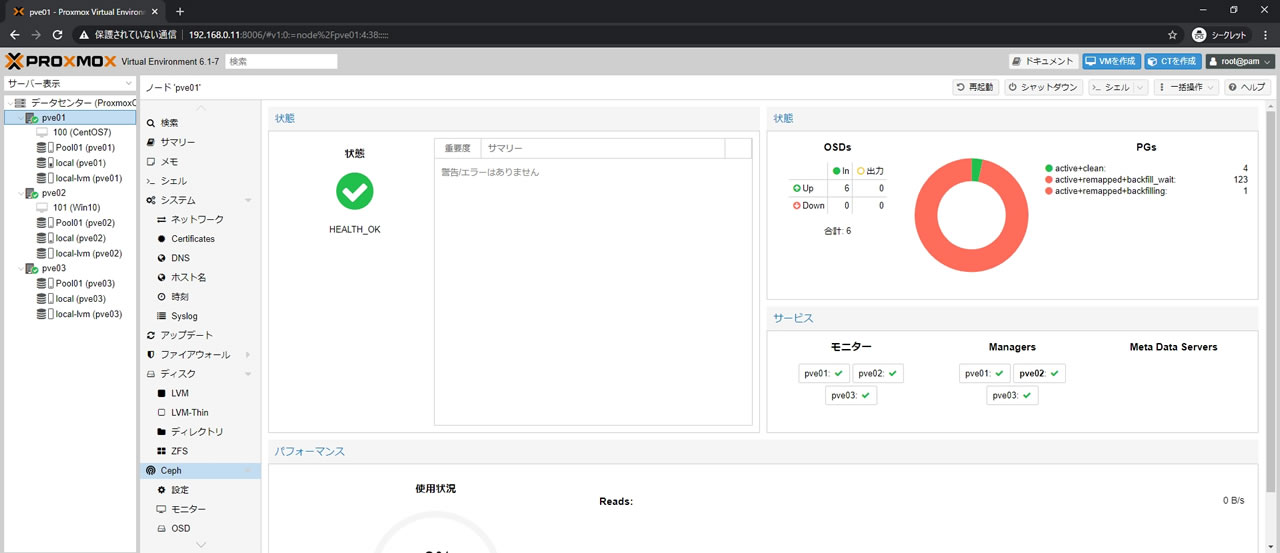
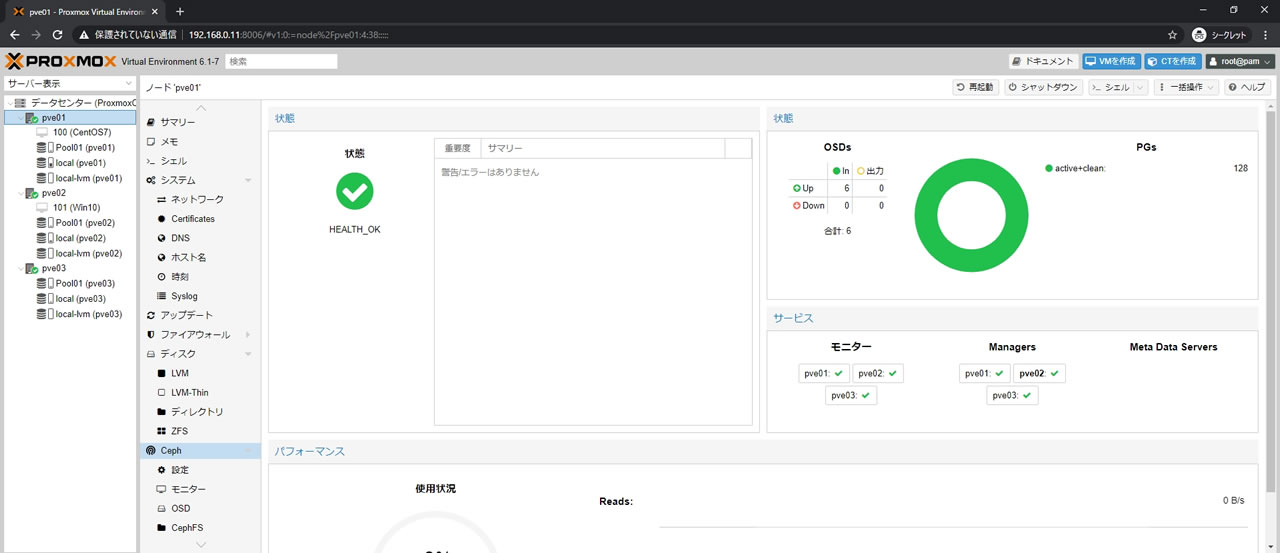
まずこの段階で全てのPGがこのようにactive+cleanでオールグリーンになるまで待ちます
今回の環境では20分かかりました
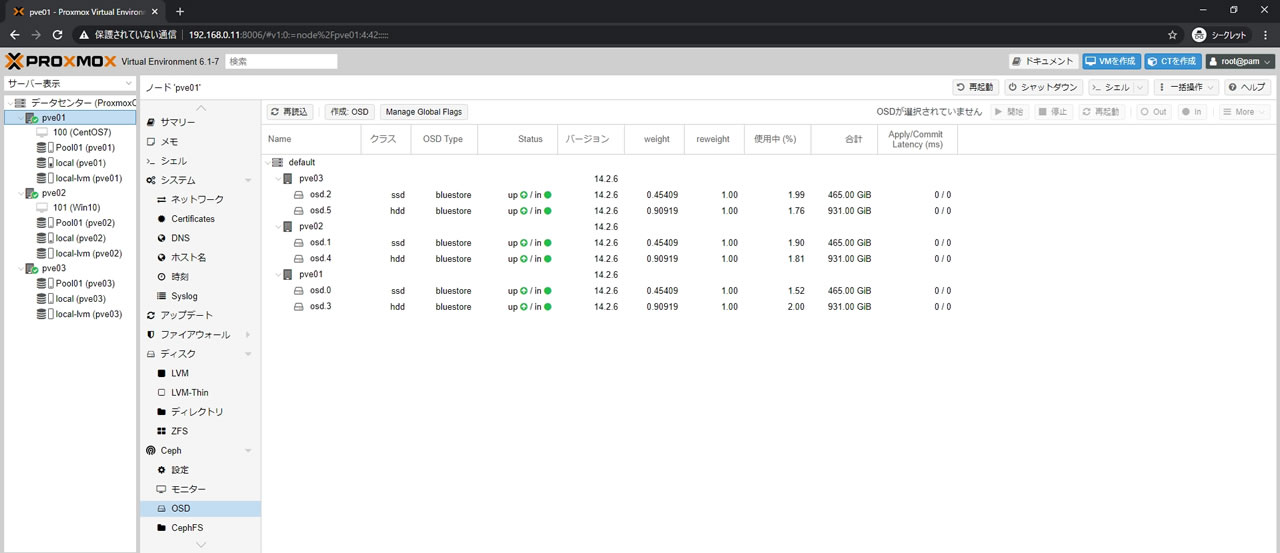
OSD一覧の様子がこちら
hddのOSDも使用中の数値が増えたことがわかります
Pool01ストレージのサマリー画面で全体容量は1.29TiBに増えました

旧OSDからデータを退避
先ほどのOSD一覧の画面にある通り
現在の状態でSSDを外すと約半分のデータがロストしてしまいますので
外す予定のSSDのOSDからデータを全てHDDのOSDへ退避させていきます
データを退避させるにはStatusの表記をup/outにする必要があるので
ssdのOSDを選択してから右上にある「Out」ボタンを選択します
Cephは設定状態へ自動でデータを移動させてくれるので
1台ごとにOutする必要はなく今回は外す3台とも一気にOutへ設定しました
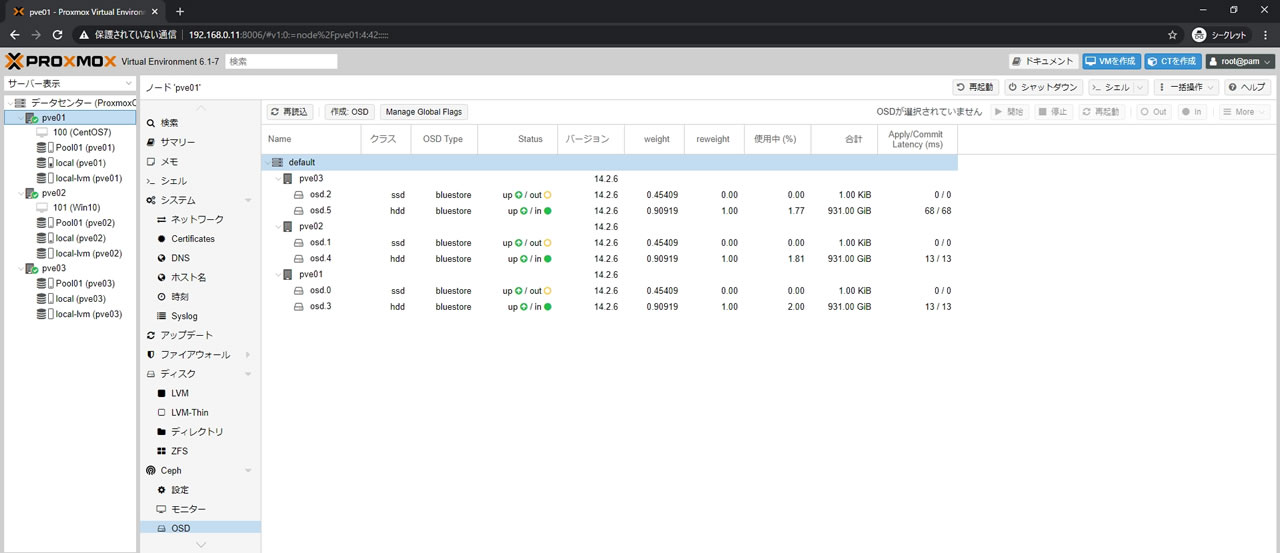
Outへ変更するとすぐにまたリマップ処理が開始されるので終わるまで待機します
OSDsの表記もinに3、出力に3になっていればOK
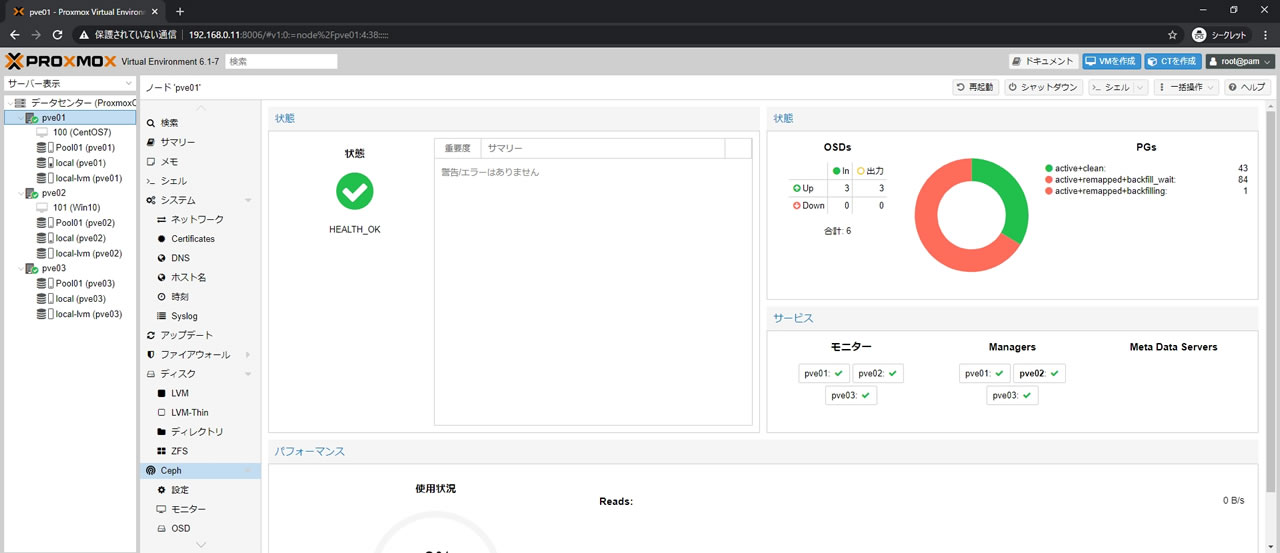
全てのPGがこのようにactive+cleanでオールグリーンになるまで待ちます
今回も所要時間は20分でした(データ容量に左右されます)
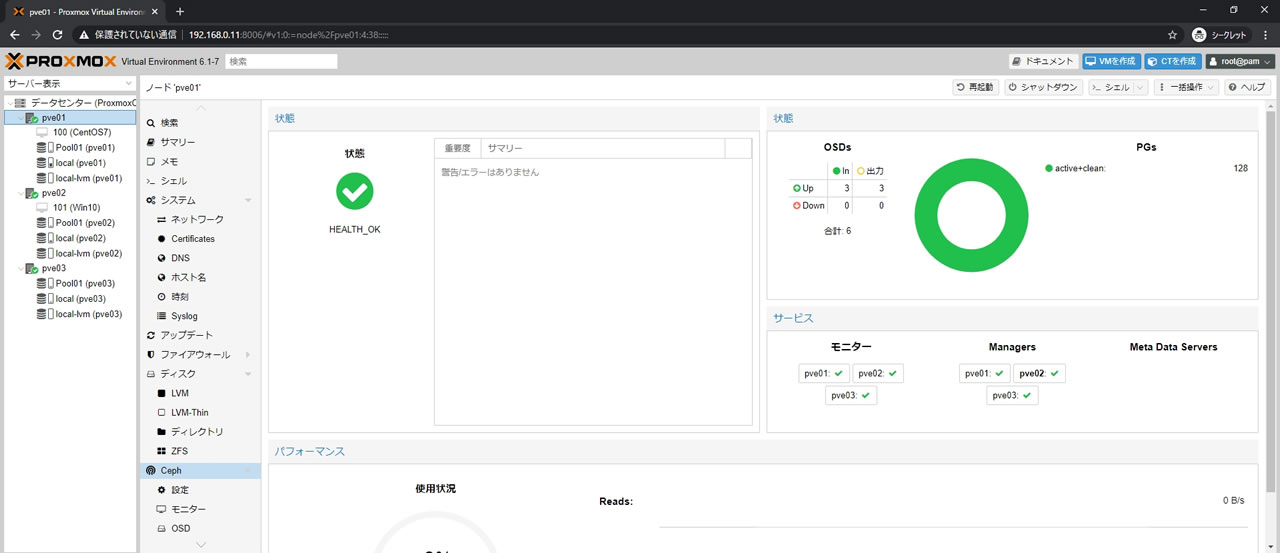
全てのPGがactive+cleanになった状態でのOSD一覧画面がこちら
outに設定したssdのOSDの使用中が0.22になり
残されたhddのOSDの方が2.64に増加しているので
ほぼ全てのデータが退避できたことが確認できます
旧OSDを削除
この状態であれば外す予定だったssdのOSDにはデータは残っていないので
OSDを選択して右上の「停止」ボタンを選択しまずはOSDを停止させます
停止するとStatusがdown/outになります
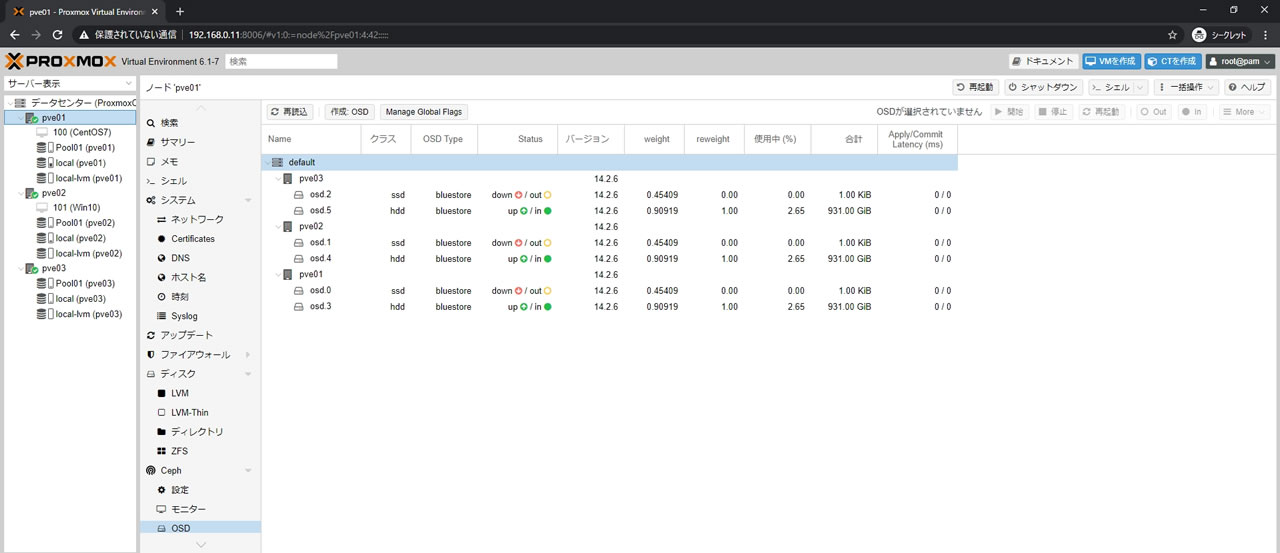
down/outに設定した後のCephサマリー画面がこちら
OSDsのカウントがDown:3になっていればOK
データ退避が終わっていればactive+cleanのままになります
この状態で全PGがactive+cleanのオールグリーンであればもうデータは安全なので
Statusがdown/outになっているssdのOSDを破棄していきます
破棄はosdを選択して右上の「More」ボタンの中にある「を破棄」ボタンを選択
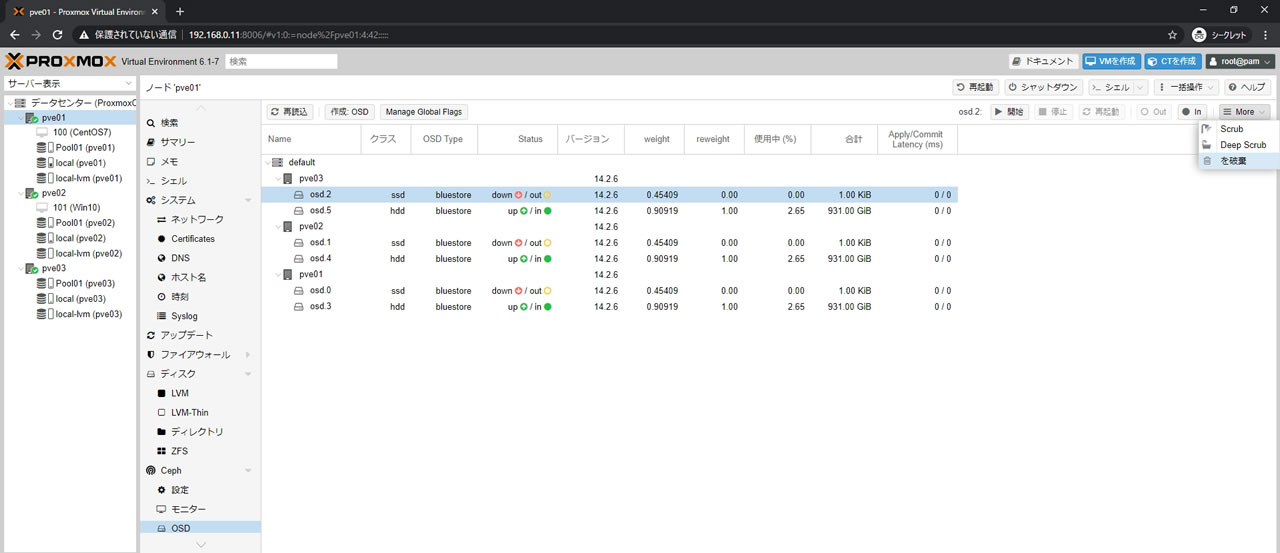
破棄の確認画面が出るので「削除」ボタンを選択して続行

3OSDを破棄してHDDのみのOSDになった状態がこちら
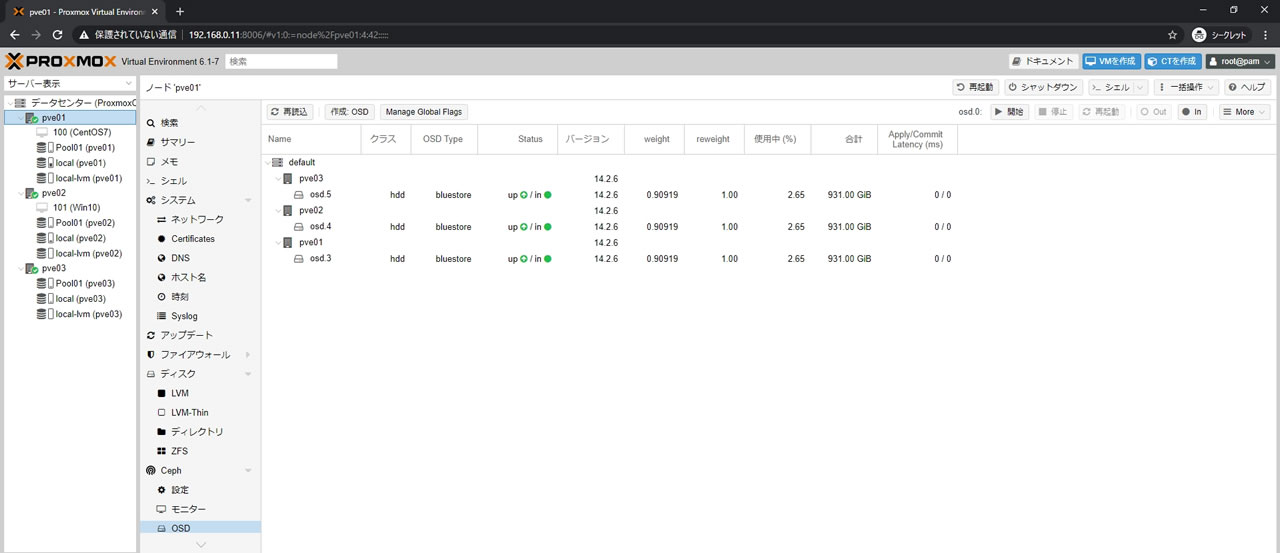
Cephサマリー画面もHEALTH_OKでPGsも全てactive+cleanなので問題なし
Pool01ストレージのサマリー画面がこちら
全体容量は883.20GiBになっていることから1TBHDDx3OSDが反映しているのがわかります
使用状況のグラフを見れば最初は512GBのSSDだったのが512GB+1TBになり
最後に1TBのHDDに落ち着いているのが確認できます
512GB+1TBの状態の間、若干右肩上がりになっているのはリマップ処理の途中だからです
まとめ
今回は3台まとめて置換しましたがSATAの空きポートがなければ1台ごとでももちろんOK
OSD操作で大事なのは各手順が終わったら必ずCephサマリー画面で
状態がHEALTH_OKで全PGがactive+cleanになっているのを確認すること
そしてUp/down/in/outの意味を理解することです
外すOSDのデバイスが動作している場合は
OSD内のデータ退避(out)→OSD停止(down)→OSD破棄の順
稼働中にハードウェアが故障しデバイスが動作しなくなった場合は
まずOSDからの反応が900秒の間になければ、CephがOSD障害と判定し
自動で該当のOSDにOutにマークをセットされ、リマップ処理が開始されますので
あとはOSD停止→OSD破棄の順になります
SATAに空きがなくてRAIDのようにHDDを抜いて同じポートに新HDDを挿す場合は
旧OSD内のデータ退避(out)→旧OSD停止(down)→旧OSD破棄→
→旧HDD取り出し→新HDD取り付け→新HDDをOSD登録
outする為の空き容量がない場合やデータ退避ができなくても他ノードが無事であれば
他ノードからのコピーで復元されますのでご安心ください
ただしCephネットワークを使ってのコピーになるので
障害ノード以外もプールへのアクセス速度はかなり低下することになります
あえてデータロストを発生させる
Cephでデータロストする条件は
同じデータを保存している各ノードのOSDで同時に障害発生した場合です
今回は実際に発生させるとどのような状態になるのかを確認したいと思います
テスト構成
各ノード2台のHDDで合計6OSDの構成になります
「同じデータを保存している」OSDがわかりやすいようにHDDは1TBと4TBを混ぜました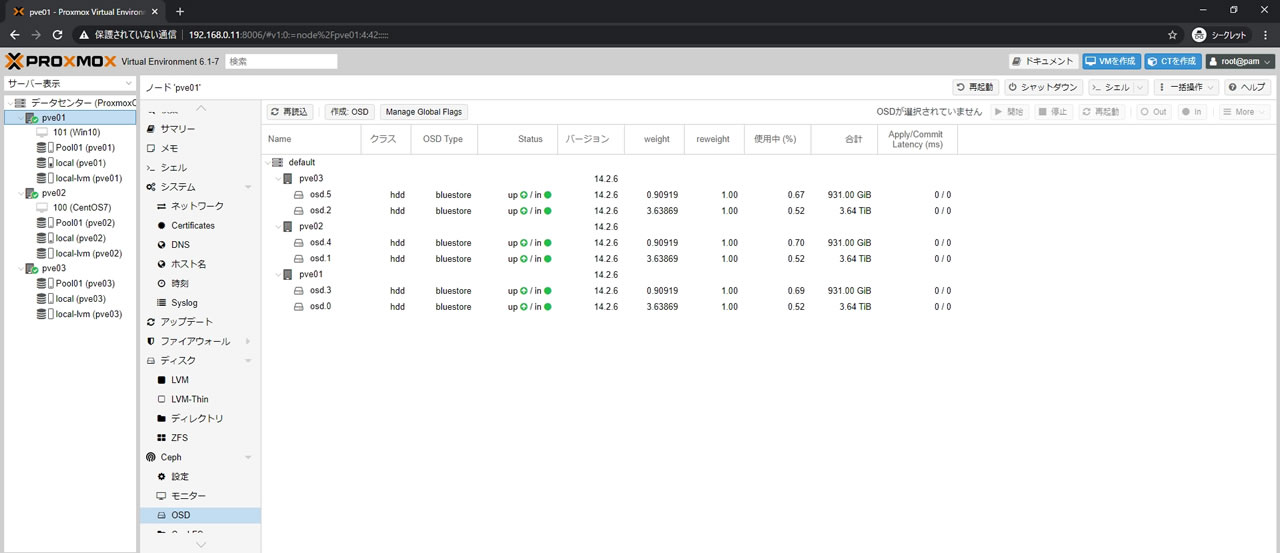
使用中の割合を見ると1TBの方が0.67-0.70で4TBの方が0.52になっているので
この状態で4TBの3台が障害を起こすとデータロストするはずです
Cephサマリーはこちら

OSDを停止
4TBのosd.0/osd.1/osd.2を停止させていきます
正しい手順ではout→down→破棄ですが
outを付けるとデータ退避してしまうので今回はoutする前にOSDを停止させます
OSD停止はOSDを選択してから右上の「停止」ボタンを選択します
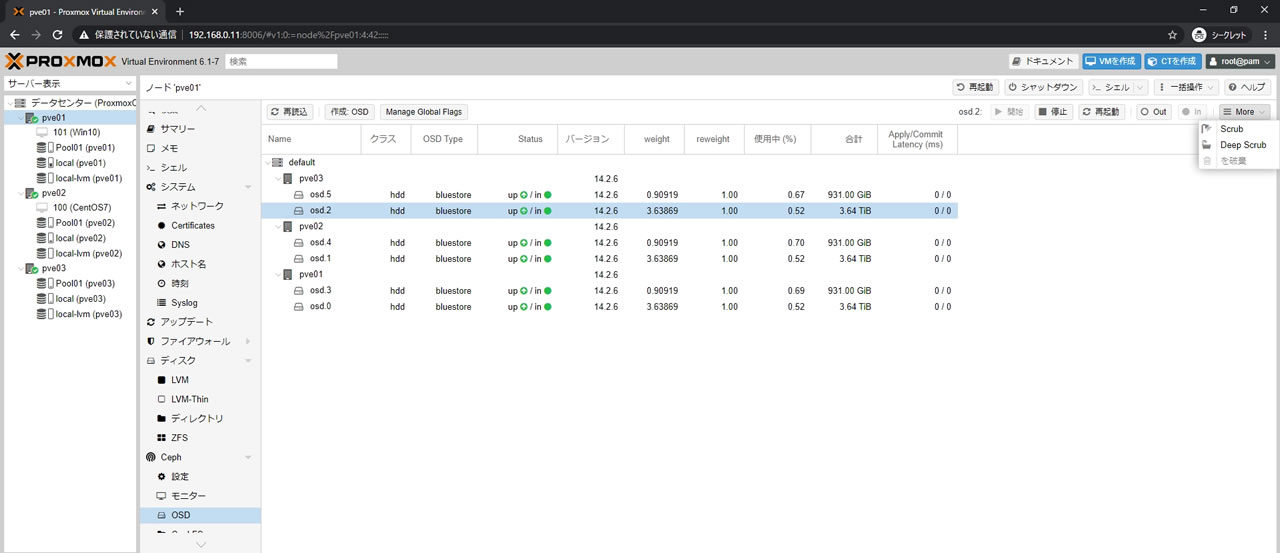
テスト的には一気にOSD破棄でも構わないのですが
画像の通りStatusがup/inの場合は破棄は選択できないようになっています
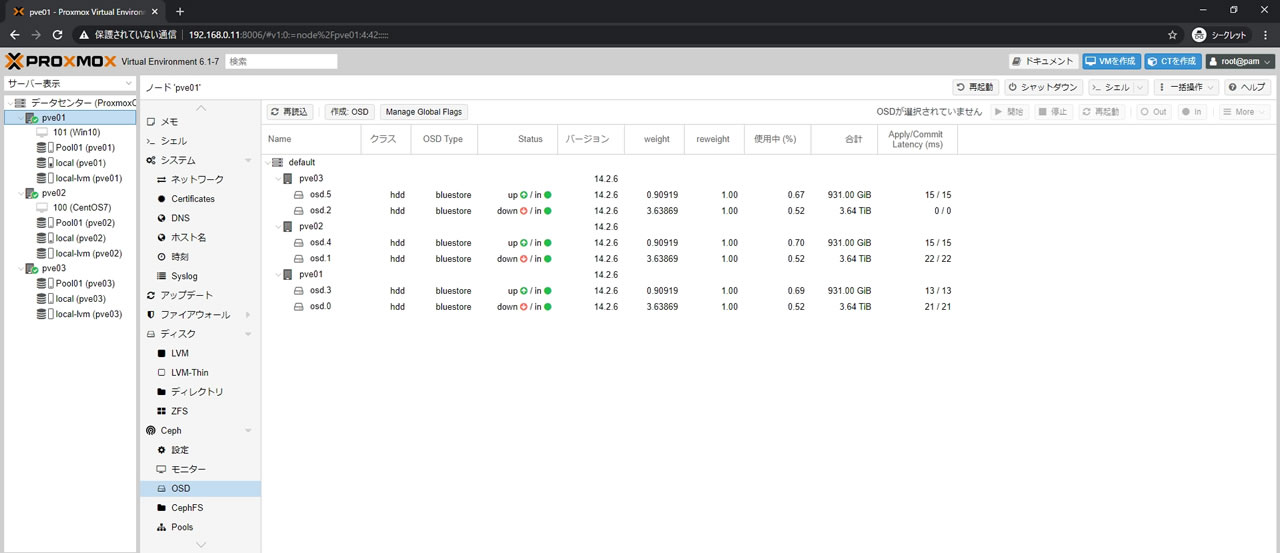
4TBのOSDを全て停止させた状態がこちら
Statusがdown/inになっているのが確認できます
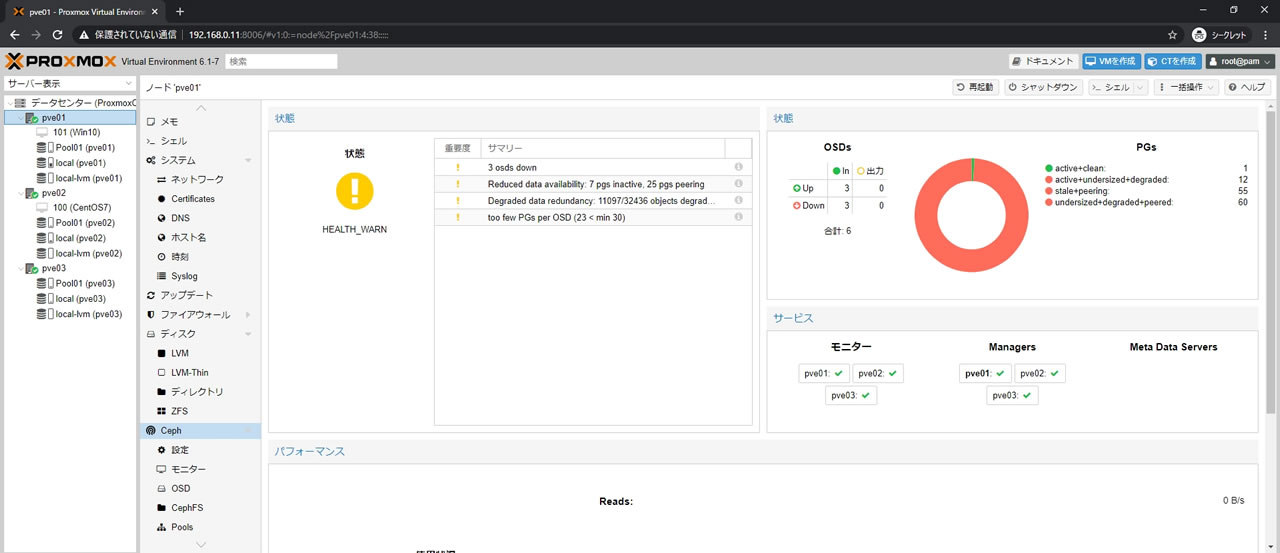
Cephのサマリー画面でもOSDsでUp:3/Down:3になっているのは確認できますが
それより目に入るのはHEALTH_WARN状態とPGsも真っ赤になっている点で
PGsに関してはactive+@@@@@がついているPGがかなり少なく
プールにある一部データへのアクセスで既に障害が発生していることがわかります
よってこの状態がデータロストです
ただデータロストと言ってもこの状態はCephからすれば
停止しているOSDを復帰させるだけで正常な状態になるわけですから
OSD復帰待ちです
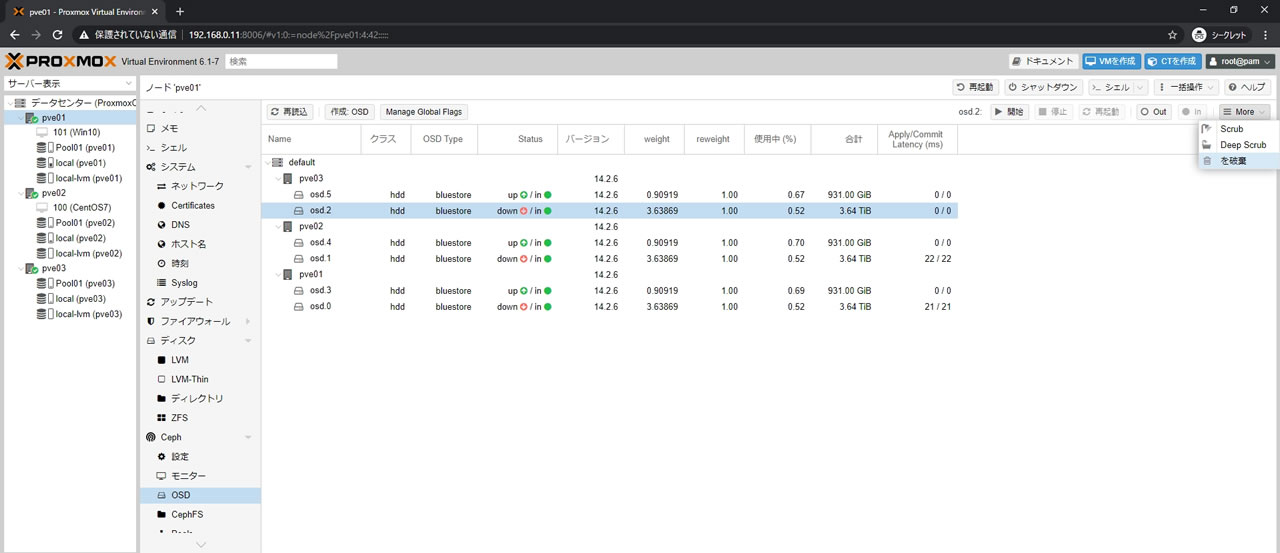
OSDの破棄
4TBのOSD自体を破棄する為
OSDを選択して右上の「More」から「を破棄」ボタンを選択
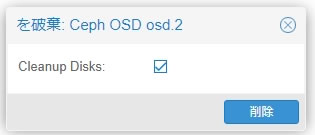
削除確認画面が表示されます
「削除」ボタンを選択するとこの状態ではエラーが発生します
エラー内容はosd is in use (in == 1)(500)
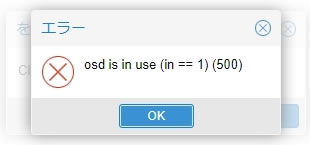
エラーはOSDがinマークになっているので削除できませんよという意味なので
削除しようとしていたOSDのStatusをdown/inからdown/outへ変更する為
OSDを選択して「Out」ボタンを選択します
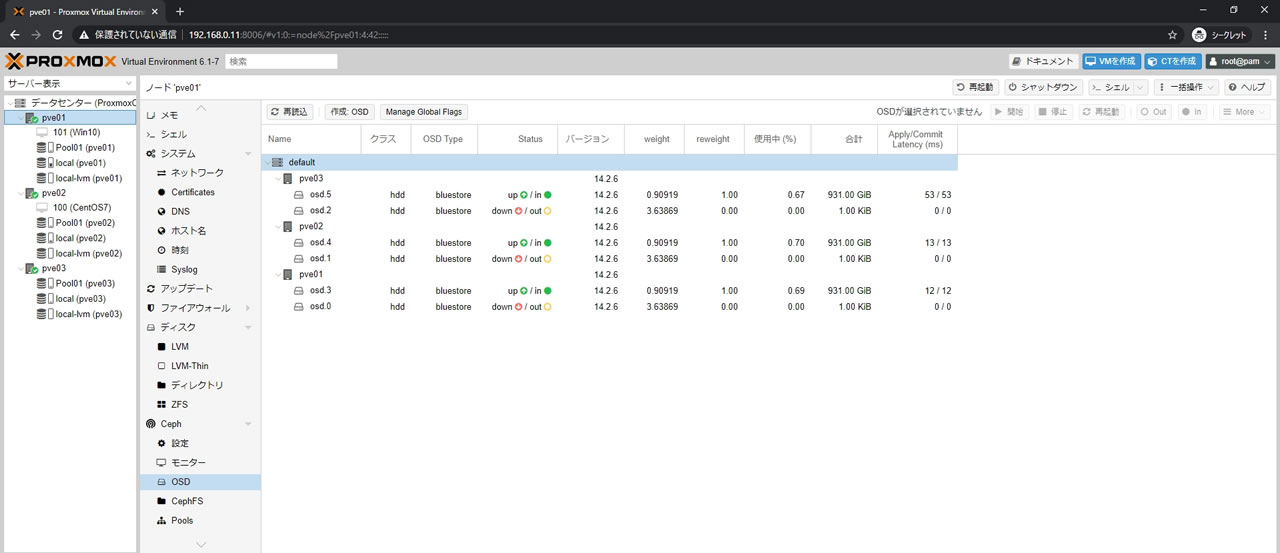
「Out」を選択したのでCephはデータ退避を開始しますが
もちろん退避するデータが入っているOSDはdown状態なので処理できません
その状態のCephサマリーがこちらです
OSDsでDown/出力が3カウントされているのが確認できます
PGsはひどいデグレード状態ですがなんとか処理している最中になります
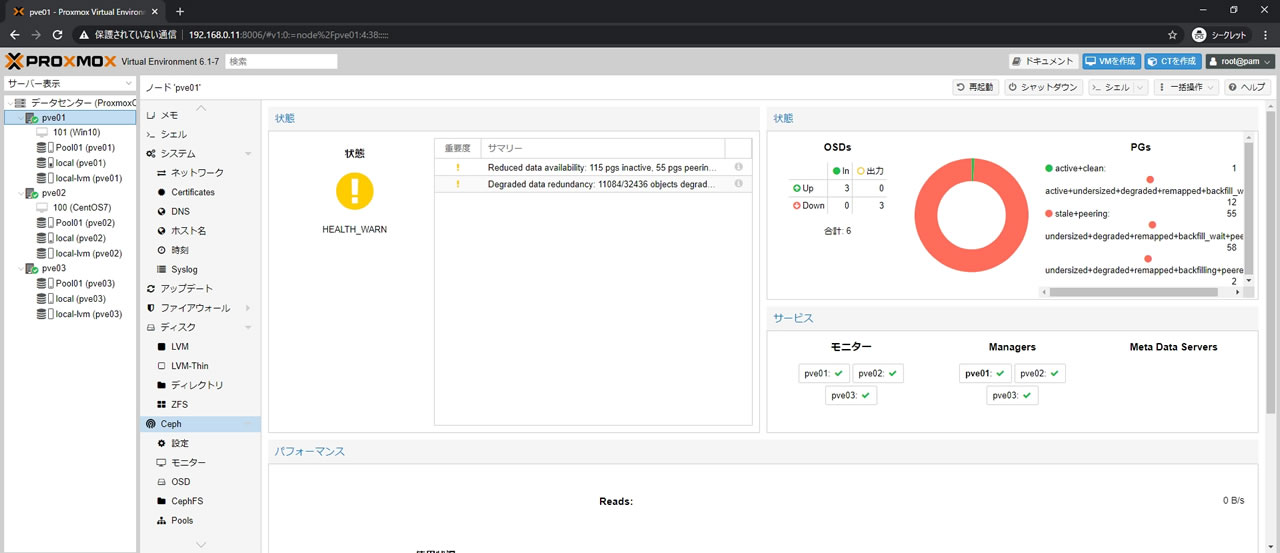
Cephの処理が落ち着いた状態がこちら
55/128のPGが非activeとなってしまっています
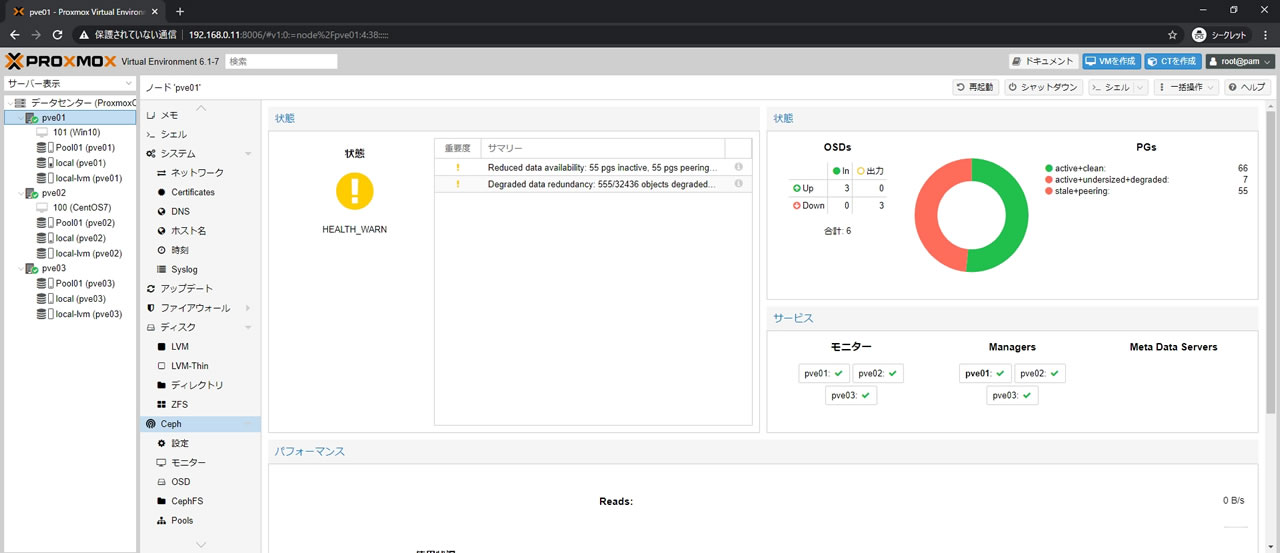
OSDのStatusをdown/outに変更してようやくOSDを破棄した様子がこちら
OSDsの表記が合計3OSDになっているのが確認できます
PGsはactive+cleanとstale+peeringになっていて
要は1TBに入っているデータがactive+cleanで4TBに入っていたのがstale+peering扱いです
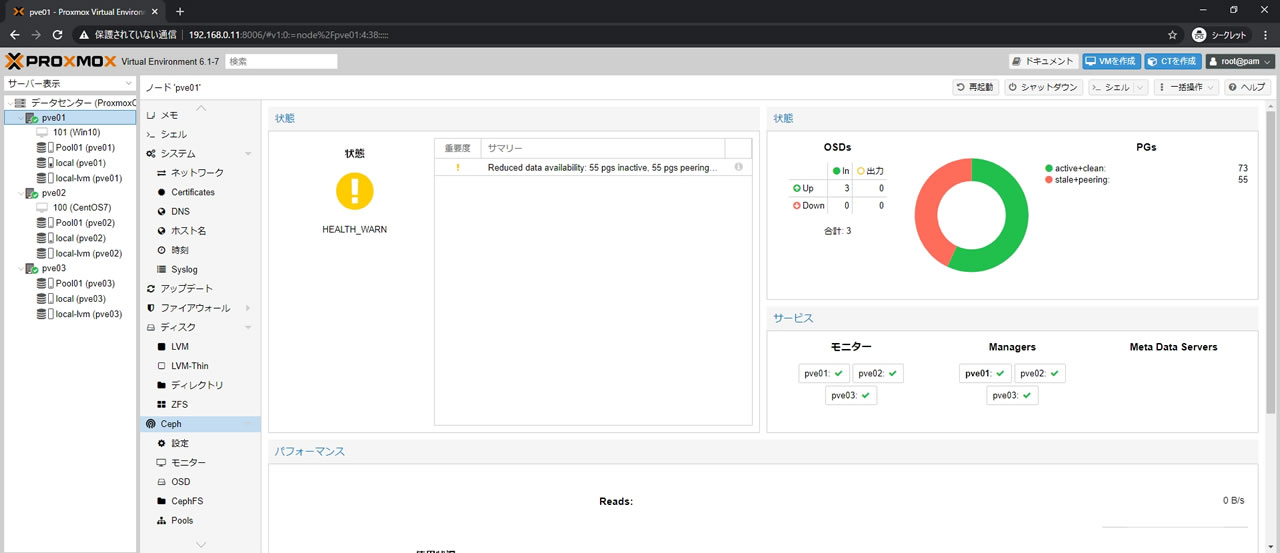
この状態では当然プールへのアクセスも不可能で
Pool01ストレージの内容画面にアクセスしても「ロード中」となり表示されません
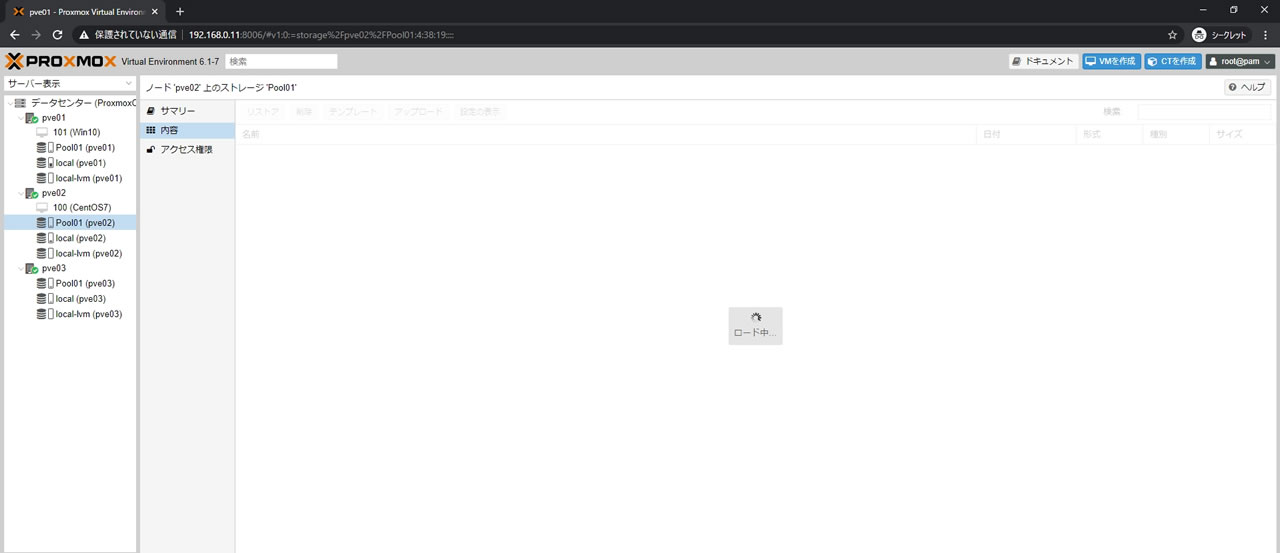
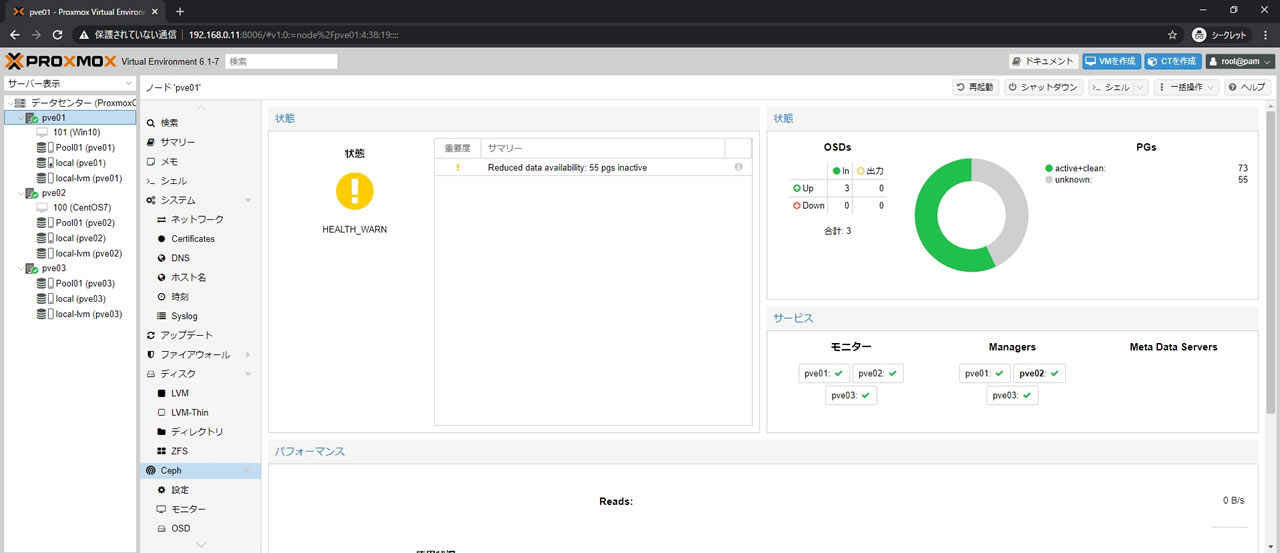
この状態でProxmoxを再起動させた後のCephのサマリー画面がこちら
stale+peeringだった55PGがunknownとなります
まとめ
Cephの3ノードクラスタは3ノード全て同じデータを保持しており
各ノードに複数のディスクを組み込めるので
RAIDでいえばRAID10のペアが3ペアになっているような状態です
RAID同様にSSDを使用する場合は総書き込み量の管理が必要になりますが
普通のRAID10と比べても単純にペア数が1つ多くなるのに加えて
各ペアが別ノードでの動作となるので物理的に隔離され、電源・マザーボードなど
ハードウェア障害によるディスク障害の同時発生リスクがかなり低くなります
ネットで調べていてもハードウェア要因でデータロストしている人はかなり少なく
複数ノードに同時に影響するような電源関係(停電など)が多かったです
ただソフトウェア要因でのトラブルはそれなりにあるので
運用前にはただセットアップするだけでなく障害テストも実施するのが賢明です
今回のデータロストテストでわかる通り、操作に対して警告等はほぼないので
手順をミスするだけで簡単にプール停止・崩壊しますのでご注意ください
とりあえずoutしてCephサマリーを確認するのが大切です
最後に
HDDやSSDの交換作業は長期運用する場合には避けて通れない部分なので
今回チェックしてみました
CephのOSD操作はDB/WALでも感じましたが
置換というより「追加して削除」の方法が一番対応しやすい気がします
というわけでRAIDのホットスペアのように
各ノード内でデバイス1台に障害が起きても
すぐoutできるような空き容量を常に確保しておくか
SATAなどメンテナンス用空きポートを1つ用意しておくと
作業の手間が変わってくると思います
速度検証記事と違って今回の作業は実機がなくてもVM環境で試せるネタなので
Proxmox+Cephを検討している人はお試しあれ

コメント